Audiometria vocale per via aerea
Dal momento che l’audiometria tonale misura la sensibilità del soggetto per toni puri (con la quale possiamo documentare il tipo e l’entità della perdita uditiva alle varie Frequenze),è evidente che offre una valutazione solo quantitativa della funzione uditiva, possiamo considerare l’audiometria vocale come una tecnica prevalentemente qualitativa atta a misurare la capacità del sistema uditivo ad interpretare la voce umana. Tutto il sistema uditivo, quindi, deve essere intatto perché il processo di comunicazione verbale possa verificarsi.
L’audiometria vocale viene adoperata per la valutazione di questo processo così complesso ed i suoi risultati possono essere usati in numerosi contesti: la diagnosi differenziale dei vari tipi di ipoacusia; la valutazione e l’adattamento di protesi acustica; «valutazioni pre-post» riguardanti gli impianti cocleari, gli interventi otochirurgici, la riabilitazione audio-foniatrica, la valutazione del grado di disabilità sociale e l’audiologia forense.
Lo stimolo può essere inviato per via aerea in campo libero o in cuffia e consiste in logotomi (consonante-vocale-consonante-vocale) senza senso compiuto (preparate da Azzi per la lingua italiana1950), parole bisillabiche a senso compiuto (preparate da Bocca – Pellegrini per la lingua italiana1950), frasi normali a senso compiuto (preparate da Bocca per la lingua italiana1950),sostituite da Cutugno et Al nel 2000, frasi sintetiche senza significato ma corrette sintatticamente proposte da Jerger (preparate da Antonelli – Barocci – Mantovani per la lingua italiana 1977) , solitamente 10-20 per lista, che sono inviate al paziente ciascuna a una determinata intensità, in cuffia o in campo libero. Il paziente deve ripetere le parole o le frasi, mentre le risposte, giudicate dall’esaminatore, sono espresse in o/o di riposte corrette. I dati permettono di definire una funzione d’intelligibilità (% delle risposte corrette sulle varie intensità cui viene inviata ogni lista). Come per ogni funzione psicometrica i punteggi variano da 0 a 100% con un tipico andamento sigmoidale. All’interno di questa variazione è invalso l’uso di identificare sulla funzione tre tipici punti: l’intensità di stimolazione in cui si raggiunge il 100% (definita “soglia di intellezione”),l’intensità in cui si raggiunge il 50%( “soglia di percezione”), l’intensità in cui si raggiunge lo 0% (“soglia di detezione”).
Tale materiale vocale è normalmente fornito su CD dal costruttore dell’ audiometro
PROVE AUDIOMETRICHE VOCALI DÌ ROUTINE
Presentazione
Campo libero
Il paziente è seduto in mezzo ad una stanza di fronte a due altoparlanti posizionati ad un angolo di 45 gradi azimut per la riproduzione di condizioni di ascolto stereo fonico. Questa è la disposizione normale per le prove vocali anche se alcune procedure speciali (le prove con competizione, l’audiometria direzionale, le procedure per l’adattamento protesico, ecc.) potrebbero richiedere un diverso posizionamento e gli altoparlanti.
Spesso le prove vocali vengono eseguite a viva voce, ad esempio per la valutazione della competenza verbale nei bambini o della capacità di lettura labiale nei sordi gravi e profondi. Ciò comporta la trasmissione del messaggio verbale a voce sussurrata o di conversazione e non prevede l’uso di attrezzature particolari. Tuttavia, questa modalità di presentazione comporta anche degli svantaggi: l’accento o il dialetto degli interlocutori possono variare enormemente; inoltre, è difficile, nel parlare mantenere la voce ad un livello di volume costante. Di conseguenza è necessario monitorizzare la voce mediante un fonometro per ottenere dei risulta coerenti.
Cuffia
Alternativamente, il messaggio verbale può essere trasmesso al paziente tramite cuffia. In teoria, l’esaminatore potrebbe anche presentare il materiale verbale usando direttamente il microfono in dotazione con l’audiometro ma anche in questo caso sorgono dei problemi di calibrazione e di monitoraggio della voce. E evidente che la riproduzione registrata e standardizzata del messaggio, dove la voce in uscita è controllata e monitorizzata direttamente dal sistema di riproduzione, è un sistema molto più attendibile ed è da preferirsi per l’applicazione delle prove cliniche di routine.
IL MATERIALE FONETICO
Il materiale fonetico impiegabile nell’audiometria vocale corrente può essere rappresentato da:
— liste di parole monosillabiche a senso compiuto (ma la lingua italiana ne è povera);
— liste di parole bisillabiche a senso compiuto (Tabella 1);
— liste di frasi;
— liste di unità verbali prive di significato (logotomi).
Si può senz’altro affermare che le liste di parole bisillabiche costituiscono il materiale verbale più frequentemente impiegato nelle prove verbali di routine. Gli elementi che costituiscono le liste di parole devono rispondere ad un certo numero di condizioni: a) le parole devono essere a pronuncia fissa; b) non devono correre ad alcun equivoco, cioè non devono essere a doppio senso; c) devono far parte, possibilmente, del vocabolario usuale del soggetto; d) in una lista tutti i fonemi di cui si compone il linguaggio parlato devono essere presenti; e) in ciascuna lista i differenti fonemi si devono trovare circa nella stessa proporzione che nel linguaggio parlato; f) la difficoltà media degli elementi di ciascuna lista deve essere costante.
Ove i punti d), e), f), siano rispettati le liste di parole possono essere considerate foneticamente bilanciate.
| LISTA A | LISTA B | LISTA C | LISTA D | LISTA E |
| Cielo | Nudo | Rete | Ira | Fiele |
| Era | Quindi | Campi | Tarma | Orlo |
| Tordo | Spina | Prova | Chiesa | Cento |
| Alpi | Giunco | Tesa | Unto | Piesi |
| Freno | Sete | Lunga | Niente | Tempo |
| Chiuso | Venti | Bravi | Zia | Strada |
| Sarti | Lei | Urli | Gelo | Mai |
| Radio | Seno | Lire | Scopa | Calda |
| Bionda | Marzo | Versi | Ponte | Onde |
| Ali | Sua | Lega | Neo | Tela |
| LISTA A | LISTA B | LISTA C | LISTA D | LISTA E |
| Santi | Capre | Zelo | Male | Lana |
| Chiese | Orto | Perle | Arma | Vesti |
| croci | Gente | Luna | Certi | Corda |
| Corte | Sesso | Erba | Sera | Neve |
| Avo | Cuoio | Lampo | Morte | Punti |
| Miele | Quarto | Zia | Nilo | Astro |
| Unghia | Naso | Villa | Dio | Piede |
| Finto | Preti | Assi | Lite | Piena |
| Uovo | Ghianda | Pende | Dentro | Gelso |
| Ridi | Una | Sfida | Alba | Nidi |
ESECUZIONE PRATICA
Per eseguire l’audiometria vocale l’esaminatore opera all’esterno della cabina in ambiente silente (possibilmente in precabina) ove è situata anche l’apparecchiatura audiometrica.
L’esaminando è posto in cabina dopo aver ricevuto chiare istruzioni sulla prova e sul modo di fornire le risposte.
Il materiale verbale una volta veniva prodotto dalla viva voce dell’esaminatore, il quale leggeva le liste al microfono, oggi viene riprodotto da CD o è inserito direttamente nell’audiometro. L’esaminando può ricevere tale materiale, così come nell’audiometria tonale, per via aerea (campo libero e cuffia) o per via ossea. In più si può studiare se il comportamento del soggetto si modifica, qualora venga associata la lettura labiale. L’esaminando potrà fornire le risposte ripetendo oralmente al microfono le parole che man mano gli vengono presentate, oppure scrivendole su apposite schede. Il metodo migliore è quello di inviare dapprima parole a valori di intensità sopraliminari, di comoda udibilità, si discende quindi verso valori di soglia ed infine si inviano parole alle massime intensità consentite.
L’AUDIOGRAMMA VOCALE
Venendo alla tecnica di esame il materiale vocale viene presentato, dopo essere stato dosato in intensità dall’attenuatore dell’audiometro (dB SPL), o mediante cuffia o in campo libero tramite due altoparlanti posti ad un angolo di 45° dall’asse occipito-nasale all’altezza delle orecchie ad una distanza di 1.20 m. Il paziente è invitato a ripetere il messaggio a viva voce nell’intervallo fra un messaggio e il successivo.
Vengono presentati 10 messaggi per serie e l’esaminatore valuta percentualmente le risposte corrette per ogni serie.
La percentuale delle risposte viene graficata su apposito audiogramma – audiogramma vocale – con la stessa semantica grafica dell’audiometria tonale (Fig.1).

Fig.1 Grafico per l’audiometria vocale. Le curve di articolazione già stampate sono quelle ottenute in soggetti normoacusici per i vari tipi di materiale verbale
L’audiogramma vocale presenta 3 soglie:
La soglia di detezione corrisponde al valore di intensità sonora in cui il messaggio verbale risulta “appena percepibile”: la parola non viene percepita e compresa come tale, ma come suono generico, quindi la percentuale di intelligibilità è dello 0%., la soglia di percezione ove il soggetto percepisce il significato corretto del 50% dei messaggi, la soglia di intellezione ove il soggetto percepisce il significato corretto del 100% dei messaggi.
La linea che unisce le tre soglie è detta curva di articolazione, ha normalmente una forma a S italica ed è riportata sull’audiogramma nell’andamento per il vario materiale per il soggetto normale.
Anche in audiometria vocale può essere necessario mascherare e le regole di base sono quelle del mascheramento tonale, qui però viene impiegato come rumore mascherante il rumore rosa o il rumore o, per tests particolari si può a volte usare come mascheramento un messaggio verbale competitivo o rumore di “cocktail party” costituito da insieme di voci e rumori sociali.
La valutazione delle risposte viene fatta quantitativamente calcolando di quanti dB la soglia di percezione si allontana dall’analoga soglia del normale e qualitativamente analizzando le caratteristiche morfologiche della curva di articolazione, potremo osservare in tal caso 6 tipologie di curve vocali patologiche, fermo restando che per tutte e 6 vi è una deriva verso destra (Fig. 2):

Fig.2
– a: curva raddrizzata, ha forma ad S ma è meno inclinata della curva normale: si reperisce in genere nelle ipoacusie di trasmissione con perdita prevalente nei gravi (otosclerosi).
– b: una curva parallela alla curva normale e solo shiftata a destra, sarà la risposta tipica nelle ipoacusie trasmissive e la misura in dB dello shift esprimerà l’intensità del deficit trasmissivo (gap medio VO-VA per le frequenze del parlato)
– c: curva obliqua: presenta una maggior pendenza verso destra specie nella parte alta. nel senso che raggiunge più lentamente. cioè con maggiori incrementi di intensità, il 100% di discriminazione. E indice di lieve distorsione alle alte pressioni sonore e quindi di ipoacusia con recruitment incompleto.
– d: curva a plateau: è molto obliqua e non raggiunge la soglia di intellezione ma ad un certo livello di intensità diventa orizzontale, ad indicare fenomeni di distorsione per cui ulteriori aumenti di pressione sonora non migliorano la discriminazione. Si osserva nelle ipoacusie cocleari con marcato recruitment. una curva spostata a destra ma con inclinazione superiore a quella del normale e che raggiunge la soglia di intellezione tipica delle ipoacusie percettive cocleari lievi
– e: curva a cupola: è simile alla precedente ma alle alte intensità ridiscende lievemente verso il basso. E’ un indice ancora più evidente di distorsione da recruitrnent cocleare.
– f: curva con roll-over: è caratterizzata da una notevole pendenza, da un breve plateau a livelli non superiori al 50-60% di identificazione e da una rapida caduta dopo il plateau che può riportarla al livello 0% tipica delle ipoacusie percettive retrococleari o cocleari assai gravi. Questo aspetto sta a significare che l’aumento dell’intensità sonora peggiora l’intellegibilità fino ad annullarla completamente ed è indice di elevatissimi fenomeni di distorsione del messaggio vocale quali si verificano nelle lesioni del nervo acustico. Infatti, la diminuzione del numero di fibre nervose fun7ionanti altera la codificazione delle componenti del messaggio ad alta frequenza (componenti sulle quali si basa la possibilità di discriminare il linguaggio verbo-acustico) e questa alterazione cresce col crescere dell’intensità dello stimolo dal momento che il reclutamento di fibre legato all’incremento dell’intensità sottrae fibre disponibili per la codificazione della frequenza. Si può verificare che una curva vocale molto alterata con roll-over completo si associ ad un audiogramma tonale solo lievemente compromesso o con soglia innalzata soltanto per le alte frequenze (dissociazione verbotonale o regressione fonemica): questo reperto è indicativo di sofferenza neurale alla quale si associ una patologia dei nuclei del tronco encefalico.
La curva di articolazione esprime graficamente la funzione di intelligibilità, ma male si presta ad una definizione che non sia di tipo grafico, inoltre in campo clinico non sempre la soglia di intellezione viene raggiunta e pertanto è stato proposto la sua sostituzione con il valore di intelligibilità massima raggiunto. Sintetizzare la funzione di intelligibilità con i tre indici comporta tuttavia una perdita di informazioni preziose sia in campo diagnostico clinico che protesico, è stato pertanto proposto di definire la risposta vocale in base all‘area sottesa dalla funzione grafica espressa in unità arbitrarie (numero di quadratini del grafico sottesi ad es.) unitamente ad un indice SUI (Sensitivity Understanding Index) calcolato con la seguente formula (5/1)
| (Valore di intelligibilità massima-I max– + valore di intelligibilità a 110 dB-I 110dB-) /2 |
| SUI= ——————————————————————————————5/1 |
| valore alla soglia di percezione —I 50%- |
I test audiometrici vocali sono stati usati principalmente per la documentazione di danni centrali, danni per i quali tale materiale è specifico e pertinente, è merito principale italiano lo studio di tests vocali sensibilizzati per documentare e localizzare la sede centrale del danno, I ‘avvento della documentazione iconografica (Tomografia assiale computerizzata — TAC — e Risonanza magnetica nucleare — RMN —) hanno reso superfluo l’uso clinico routinario di tale tecniche, ancora in uso in campo di ricerca.
Ricorderemo a titolo conoscitivo:
fra le prove sensibilizzate monoaurali i tests con le:
Frasi accelerate di Bocca e Calearo
Frasi interrotte di Bocca
Frasi filtrate di Bocca
Nelle ipoacusie trasmissive, le funzioni di intelligibilità per tali prove hanno lo stesso andamento di quelle rilevate con materiale vocale normale.
Nei deficit neurosensoriali, e in special modo nelle lesioni centrali e nelle ipoacusie idropiche a curva piatta, vi è un peggioramento della funzione maggiore di quella ottenuta con materiale non sensibilizzato.
Analogo maggior peggioramento si ha inoltre col progredire dell’età del soggetto.
Fra i tests binaurali ricordiamo le prove di:
Integrazione binaurale di Matzken
Sommazione di Bocca
Con voce commutata di Bocca e Hennebert
Di Katz con parole spondaiche
Tali prove indagano l’importanza delle vie uditive crociate, esclusivamente stimolate nei test binaurali che inibiscono invece le vie dirette.
Altri tests vocali sono stati proposti per valutare la capacita del sistema nervoso centrale di identificare correttamente il messaggio primario in presenza di un secondo messaggio disturbante presentato controlateralmente, ipsilateralmente o in campo libero.
Quanto detto è valido per le liste di parole bisillabiche; per le frasi la curva normale si presenta più verticalizzata, mentre per i logotomi si presenta più orizzontalizzata: ciò è legato al diverso ruolo giocato dal fattore ridondanza. L’audiometria vocale è un test di valutazione della funzionalità uditiva che utilizza lo stimolo verbale.
Le due misure standard di percezione del linguaggio sono la SOGLIA DÌ RICEZIONE DEL LINGUAGGIO e il PUNTEGGIO DÌ RICONOSCIMENTO DELLE PAROLE( soglia di percezione del linguaggio).
LA SOGLIA DÌ RICEZIONE DEL LINGUAGGIO è il livello più basso (in decibel) con cui il paziente può ripetere accuratamente il 50% di una serie di bisillabi, parole bilanciate (spondaiche, cioè di due sillabe lunghe). La soglia di ricezione del linguaggio, di solito, è entro i 5 dB del tono puro medio. Perciò la soglia di ricezione del linguaggio e il tono puro medio potranno essere usati come controlli l’uno per l’altro, convalidando anche le risposte di soglia.
IL PUNTEGGIO DÌ RICONOSCIMENTO DELLE PAROLE ( soglia di percezione del linguaggio)rappresenta le capacità del paziente di comprendere al massimo (p. es., discriminare, udire chiaramente, riconoscere) i suoni vocali. Esso viene misurato presentando parole monosillabiche foneticamente bilanciate (solitamente, un elenco di 25) a un livello di volume confortevole per il paziente. Le parole vengono presentate nel contesto di una frase (p. es., “mi dica la parola «barca»”, “mi dica la parola «andato»”). Il compito del paziente sarà quello di ripetere la parola finale. Il punteggio finale è dato dalla percentuale di parole ripetute correttamente. Comunque, un punteggio di 100% non preclude necessariamente la necessità di protesi acustiche. Per esempio, se il punteggio è 100% a un livello di presentazione di 85 dB (che è più forte di quello del linguaggio di una conversazione media), il paziente, quasi certamente, avrà bisogno e trarrà beneficio dalle protesi acustiche.
AUDIOMETRIA VOCALE (I°APPROFONDIMENTO)
L’audiometria vocale comune consiste nel valutare la comprensione delle parola. Si conoscono sempre più le basi fisiologiche della percezione della parola grazie ai lavori di neurofisiologia sensitiva che utilizza i suoni complessi. La comprensione di una parola implica due meccanismi successivi. Il primo meccanismo consiste nel codificare la parola nel sistema uditivo periferico. Quindi, sono messi in gioco i meccanismi di riconoscimento della parola. Pare che esistano due tipi di trattamento centrale della parola che funzionano parallelamente: un trattamento adeguato alle caratteristiche spettrali della parola e un trattamento delle caratteristiche dinamiche. Le informazioni spettrali contenute nella parola possono essere codificate sia da variazioni di scarica in funzione della frequenza caratteristica delle fibre del nervo acustico (meccanismo messo in gioco principalmente per le consonanti non fricative), sia da una sincronizzazione delle scariche dei potenziali d’azione in una fibra del nervo acustico con i componenti frequenziali dello stimolo (meccanismo messo in gioco principalmente per la distinzione fra le vocali Borg E.1973; Dauman R.1986;Delgutte B,1984; ,)
Le informazioni dinamiche rivelano i picchi che si producono durante gli attacchi bruschi della parola. Questa rivelazione fornisce, in particolare, un’informazione sul modo di articolazione delle consonanti. Permette anche di guidare le tappe del trattamento ulteriore del segnale, indicando le particolarità ricche di informazione di quest’ultimo.
La valutazione delle capacità di percepire e discriminare informazioni acustiche di tipo fonetico è sicuramente più “realistica” rispetto alla valutazione tonale, ed in grado di mettere maggiormente in luce le eventuali difficoltà di comunicazione in termini sociali.
La voce umana è il mezzo con cui i simboli della comunicazione verbale vengono codificati in veste linguistica. Il linguaggio, come l’udito, fa parte di un sistema complesso fono-audiologico nel quale entrano in gioco meccanismi superiori di analisi, integrazione, elaborazione psichica, espressione prassica articolatoria.
L’audiometria vocale consente una valutazione corretta della funzionalità di tutto il sistema uditivo e anche delle strutture extrauditive, costituendo un test efficace nella diagnosi delle disfunzioni uditive superiori che si realizzano in presenza di patologie del sistema nervoso centrale.
Tale valutazione però non è scevra da difficoltà operazionali e richiede tempi di esecuzione maggiori.
Un rinnovato interesse e slancio clinico verso questa interessante ma complessa strategia di valutazione audiometrica deriva dalle attuali esigenze legate agli impianti cocleari (vedi il relativo capitolo). I criteri di selezione del malato per tale tipo di intervento chirurgico prevedono infatti che sia fatta una valutazione clinica sia sui residui uditivi in termini di soglia tonale sia soprattutto sulle capacità residue di percezione verbale.
I campi specifici di interesse dell’audiometria vocale sono:
— la valutazione della terapia protesica nella sordità;
— la selezione nei pazienti candidati agli impianti cocleari;
— lo studio delle sordità “centrali”;
— la funzionalità uditiva prima e dopo interventi chirurgici dell’orecchio;
— il monitoraggio della riabilitazione protesica ed implantologica;
— l’audiologia medico legale.
La misura della intelligibilità di un messaggio verbale è lo scopo dell’audiometria vocale. Per definire però il concetto di intelligibilità è necessario fare alcune precisazioni. I processi centrali di analisi e di produzione del linguaggio parlato si articolano in tre stadi:
a) recezione e discriminazione;
b) integrazione o identificazione;
c) comprensione o stadio concettuale-simbolico.
In molti casi una prestazione verbale può non coinvolgere tutti e tre gli stadi suddetti (per es. nel linguaggio ecoico del bambino, nella ripetizione di parole appartenenti a lingua che non si conosce ecc.). Allorché il compito di un soggetto sia quello di ripetere graficamente od oralmente un messaggio verbale fatto di parole o anche di frasi, non si potrà agevolmente stabilire quanti e quali stadi siano attraversati. Il concetto di intelligibilità implica il semplice riconoscimento o anche la comprensione del messaggio? Impossibile dare quindi una definizione inequivocabile del concetto di intelligibilità.
FATTORI INFLUENZANTI L’INTELLIGIBILITÀ
L’intelligibilità, comunque concepita, è influenzata da tre fattori principali:
1) livello di intensità sonora del messaggio;
2) tipo di materiale fonetico;
3) presenza eventuale di fenomeni di disturbo nella via di trasmissione, nell’ambiente o nell’apparato di ricezione.
Per ciò che riguarda il primo punto esiste un caratteristico rapporto proporzionale fra intensità del messaggio e intelligibilità che prende il nome di funzione di intelligibilità. Il diagramma necessario per evidenziare tale rapporto riporta sull’ascisse i valori di intensità e sulle ordinate i valori in percentuale di intelligibilità. La curva acquista il caratteristico andamento sigmoide (S-italica), come vedremo appresso.
Il materiale fonetico influisce sulla intelligibilità mediante due meccanismi
quello della ridondanza (estrinseca) e quello della occorrenza. Col primo termine intendiamo “una quantità di informazione in eccesso che viene inserita nel messaggio in modo da fornire al ricevente la chiave per correggere eventuali errori”. E poco ridondante, per es., un fonema pronunciato isolatamente in quanto per la sua identificazione sarà necessario discriminare esattamente tutti i suoi tratti distintivi; lo stesso fonema pronunciato nell’ambito di una parola, sarà riconosciuto molto più facilmente in quanto avrà una maggiore ridondanza dovuta tra l’altro alla presenza del significato. Possiamo riconoscere, quindi, vari tipi di ridondanza verbale: a) quantitativa, legata alla lunghezza del complesso verbale; b) sintattica, relativa alla correttezza ed alla ricchezza sintattica e grammaticale dell’eloquio; c) semantica, legata al significato degli elementi verbali impiegati; d) prosodica, dipendente dalla intonazione, melodia, punteggiatura. Il concetto di “occorrenza” è intimamente legato a quello di frequenza o ricorrenza delle varie parole nella lingua e alla ricchezza di vocabolario da parte del soggetto. L’intelligibilità dipenderebbe quindi anche dal numero di forme significative della lingua apprese precedentemente e memorizzate.
Fenomeni di disturbo sull’intelligibilità del segnale sono, per es. le distorsioni prodotte artificialmente in audiometria vocale speciale (vari tipi di rumore, interruzione, filtraggio ecc. vedi appresso). Importanti fenomeni di disturbo sul segnale possono però verificarsi in varie situazioni patologiche uditive (per es. il recruitment).
INTELLIGIBILITÀ E SISTEMA UDITIVO
L’intelligibilità risulta dall’elaborazione che l’ascoltatore compie sullo stimolo verbale.
La prima categoria di fattori che influenzano la intelligibilità è quindi inerente al materiale. Ogni tipo di materiale è caratterizzato da un certo livello di ridondanza (estrinseca), definibile come un eccesso di informazione rispetto al minimo indispensabile per operare un riconoscimento (ridondanza fonemica, semantica, sintattica, distributiva, lessicale, ecc. ). Esempi di materiale a bassa ridondanza sono rappresentati da stimoli verbali inconsueti (sillabe, parole senza significato, ecc.), o acusticamente trattati (filtrati, accelerati, interrotti), o inviati contemporaneamente a messaggi competitivi.
La seconda categoria di fattori che influenzano l’intelligibilità è relativa all’ascoltatore, o meglio alla funzionalità del suo sistema di ricezione e decodifica , Secondo un modello tuttora accettato, esisterebbe una ridondanza intrinseca all’ascoltatore, definibile come un sovra-dimensionamento funzionale del sistema uditivo, che servirebbe a decodificare correttamente anche stimoli di bassa ridondanza. Esempi di bassa ridondanza intrinseca sono rappresentati prevalentemente da disfunzioni ai livelli più alti della via uditiva. Il prodotto della combinazione di diversi livelli di ridondanza, estrinseca ed intrinseca, dà luogo, a parità di condizioni di stimolazione, a diversi punteggi di intelligibilità. Disfunzioni a vari livelli della via uditiva possono pertanto influenzare l’intelligibilità del materiale verbale, in misura diversa, secondo i tipi di materiale e delle modalità di stimolazione, Schematicamente si possono distinguere le seguenti condizioni:
Difetti di conduzione dell’orecchio medio. A condizione che il messaggio sia sufficientemente amplificato, l’intelligibilità è normale, indipendentemente dalla ridondanza estrinseca del materiale.
Difetti della coclea. Provocano oltre un innalzamento di soglia uditiva, anche distorsioni percettive nella discriminazione di intensità (recruitment), frequenza e tempo, cioè in quei parametri da cui i decodificatori centrali traggono l’informazione. L’intelligibilità per materiale ridondante (parole o frasi) se inviato a livelli di poco superiori alla soglia può essere normale. Con intensità più elevate, diventando più rilevante l’effetto delle distorsioni di ricezione, l’intelligibilità può ridursi. Tale effetto può essere potenziato sotto mascheramento (rumore bianco, rumore di traffico, ecc.). Punteggi di intelligibilità ridotti possono anche verificarsi a livelli iuxtaliminari, utilizzando materiale costituito per esempio da sillabe, dove diventa più critica l’analisi temporale e di frequenza per distinguere certe transizioni fonemiche.
Difetti di conduzione neurale. Una riduzione funzionale delle fibre del nervo VIII° implica ridotti tempi di ricupero (adattamento patologico), ed in definitiva una diminuita capacità di sostenere risposte neurali persistenti nel tempo. Tale fenomeno diventa ancora più accentuato con elevate intensità. I punteggi di intelligibilità già con intensità iuxtaliminari possono essere ridotti (dissociazione tono-verbale). La riduzione risulta talvolta drammatica (roll-over) con intensità elevate o inviando il messaggio sotto un mascheramento continuo.
Disfunzioni delle vie uditive centrali del tronco. I punteggi di intelligibilità possono variare considerevolmente, in ragione della variabilità delle lesioni. Generalmente, con materiale ad alta ridondanza inviato ad intensità sopra- soglia l‘intelligibilità è normale. Utilizzando materiali a bassa ridondanza, come ad esempio frasi filtrate e accelerate, o frasi a bassa ridondanza sintattica (<sintetiche») inviate con competizione ipsilaterale, si possono osservare marcate riduzioni di intelligibilità. Resta dubbia la possibilità di localizzare la lesione all’emitronco destro o sinistro in funzione di asimmetrie dilato della intelligibilità. Infatti tali asimmetrie possono essere orno o controlaterali in relazione al livello della lesione, se a valle o a monte dell’incrociamento della via uditiva. Poiché la via uditive nel tronco è sede dei processi di interazione binaurale (lateralizzazione-localizzazione dei suoni, fusione binaurale), le lesioni d questo tratto possono produrre difetti di intelligibilità con materiali verbali speciali inviati binauralmente (test di fusione binaurale, materiale con ritardo interaurale, test che sfruttano la riduzione binaurale del mascheramento).
Disfunzioni a livello corticale (lobo temporale). Lesioni in queste sedi sono caratterizzate da una soglia tonale normale. Possono invece manifestarsi con una lieve riduzione di intelligibilità, anche con materiale a normale ridondanza, quando questo viene inviato nell’orecchio controlaterale alla lesione. Tale effetto viene potenziato utilizzando materiale a bassa ridondanza, o con prove dicotiche inviando materiale verbale contemporaneamente ad una competizione nell’orecchio controlaterale. In questo caso le conseguenze della riduzione di ridondanza intrinseca dovuta alla lesione degli analizzatori centrali del linguaggio diventano ancora più evidenti, poiché competizione e messaggio primario incidendo sugli stessi analizzatori tendono a saturane le funzioni.
Materiale fonetico
I fonemi sono gli elementi sonori più brevi che permettono di distinguere diverse parole. L’ audiometria vocale corrente è essenzialmente una prova di comprensione realizzata con le parole. Queste parole devono contenere una rappresentazione equilibrata di tutti i fonemi del linguaggio parlato. Queste parole devono, inoltre, comprendere anche lo stesso numero di sillabe, non comportare alcun equivoco e appartenere all’usuale vocabolario adattato all’età del paziente. L’istituzione di tali elenchi è stata oggetto di numerose pubblicazioni in tutte le lingue. Questi elenchi sono sia monosillabici (elenchi PB, «foneticamente bilanciati»), sia bisillabici Freyss G
Il vantaggio degli elenchi monosillabici è di evitare che ci possa essere una sostituzione mentale nella comprensione della parola. Più una parola è corta, più è difficile identificarla in assenza del contesto. Tuttavia, gli elenchi utilizzati con maggiore frequenza sono bisillabici
Tecnica di audiometria vocale comune
Deve essere realizzata in una cabina audiometrica. L’esaminatore deve spiegare al paziente il principio e la tecnica dell’ audiometria vocale il paziente deve ripetere le parole così come le coglie. Se il medico non utilizza un nastro preregistrato, ma dice le parole al paziente, il paziente non deve guardare le labbra del medico per evitare la lettura labiale (tranne che nell’esame dove si associa un’ audiometria vocale a una lettura labiale). Le regole di mascheramento sono le stesse dell’ audiometria tonale.
Gli stimoli audiometria vocale sono inviati in campo libero o tramite una cuffia con ascolto monoauricolare. Se viene utilizzato il campo libero, la calibratura deve tener conto della distanza paziente-altoparlanti. L’esame è allora binaurale. L’esaminatore può leggere le parole, lentamente e articolando, o utilizzare delle registrazioni. Gli accenti regionali devono essere presi in considerazione al fine di effettuare una prova adeguata al paziente da analizzare. La prova inizia con la ricerca della percentuale di parole comprese in una lista di dieci parole e ad alta intensità di stimolazione, cioè, al di sopra delle soglie di rivelazione delle frequenze conversazionali nell’ audiometria tonale. L’intensità della stimolazione è quindi modificata per determinare la percentuale di parole correttamente ripetute con diverse intensità. Le percentuali calcolate sono rappresentate sul diagramma dell’audiometria vocale (fig 3) . Sono necessari 5-10 punti per tracciare una curva completa.

Fig. 3 Audiometria vocale.
In alto: parametri raccolti sulle curva dell’audiometria vocale: soglia di intelligibilità (A), massimo di intelligibilità (B), percentuale di discriminazione (C).
In basso: curve ottenute in un soggetto normale con una lista di parole monosillabiche (elenco PB) (A) o con una lista di parole bisillabiche (Fournier)(B). Le curve C, D ed E rappresentano alcuni esempi di sordità di trasmissione (C), di percezione con bassa distorsione (D) o con alta distorsione (E).
METODOLOGA GENERALE
I principi generali che hanno guidato la selezione dei reattivi illustrati in seguito, hanno preso corpo progressivamente, sulla base delle esperienze cliniche e dei risultati della ricerca di gruppi di diversa estrazione (aree clinico-diagnostica, riabilitativa, linguistica) costantemente e criticamente aggiornate in base alle modificazioni che nel corso degli ultimi anni si sono constatate nell’evoluzione delle applicazioni dell’audiometria vocale. Ciò ha portato al progetto di definire dei reattivi che consentissero una ampia flessibilità di impiego per quanto riguarda la numerosità degli elementi nelle liste, le modalità di somministrazione e di risposta, le combinazioni con diversi tipi di competizione, ma al contempo fossero costituiti da campioni di linguaggio il più possibile rappresentativi del linguaggio moderno parlato, nonché calibrati al meglio per le caratteristiche fisiche.
Il materiale verbale è costituito da stimoli acustici complessi, la cui identificazione è possibile solo se il sistema uditivo possiede una soddisfacente capacità di risoluzione nel tempo e nella frequenza, oltre ad una adeguata discriminazione in intensità. I risultati dei test di audiometria vocale riflettono complessivamente queste caratteristiche del sistema uditivo, che, se valutate in modo analitico, richiederebbero una serie di test psicoacustici di lunga durata e di non facile esecuzione.
Il materiale vocale in lingua italiana attualmente a disposizione è composto da reattivi verbali di diverso grado di ridondanza e organizzazione fonemica, ed in particolare:
1) parole bisillabiche (Bocca e Pellegrini, 1950)
2) frasi a senso compiuto (Pietrantoni et Al,1956)
3) logotomi (Azzi, 1950)
4) parole per audiometria vocale infantile (Rimondini e Rossi, 1982)
5) Audiometria vocale (Cutugno F.et Al GN ReSound, 2000)
6) frasi sintetiche sec.Jerger (Antonelli et Al, 1977)
7) reattivi vocali per la valutazione delle minime capacità uditive (Prosser et Al, 1986).
Se si escludono gli ultimi due tipi di reattivi verbali, che sono utilizzati limitatamente a situazioni diagnostiche particolari, i materiali più comunemente usati sono rappresentati dalle liste di parole bisillabiche foneticamente bilanciate, e dalle liste di frasi a senso compiuto. Questi sono ancor oggi gli strumenti di riferimento per determinare la funzione di intelligibilità, e sono utilizzati quotidianamente in ogni struttura.
MODALITÀ DI SOMMINSTRAZONE
Le metodiche tradizionali prevedono il rilievo delle risposte del paziente al materiale verbale organizzato in liste, somministrato a diverse intensità. In tal modo è possibile costruire una funzione di intelligibilità, definita dalla percentuale di risposte corrette in relazione all’intensità. Normalmente 1’ intelligibilità cresce con l’aumentare dell’intensità, ottenendo una funzione psicometrica, caratterizzata da un andamento sigmoidale. Nella porzione compresa fra il 20 e l’80% di risposte corrette la funzione dimostra una ripida crescita, di circa il 10% per ogni dB di incremento dell’intensità. Tale crescita può variare in relazione ai diversi materiali ver bali impiegati, in ciò riflettendo principalmente la ridondanza propria di ciascun materiale. I livelli di intensità della funzione psicometrica corrispondenti allo 0%, 50%, 100%, vengono definiti rispettivamente soglia di detezione, percezione e intellezione.
Data la distribuzione binomiale dei punteggi percentuali, i risultati ottenuti con questa metodica presentano una alta variabilità intrinseca, dipendente soprattutto dal numero di elementi che compongono la lista e dal punto della funzione psicometrica; ad esempio, con liste di 10 items, per punteggi attorno al 50%, si associa una variabilità del 32%. Questi problemi limitano notevolmente la possibilità di controllare la variabilità intra- e inter- individuale delle prove di audiometria vocale secondo la metodica tradizionale. Per ovviare a queste limitazioni si deve aumentare considerevolmente il numero di items per ciascuna lista, oppure si può ricorrere a procedure di tipo adattivo, cioè a metodiche di somministrazione in cui la conduzione della prova e in particolare l’intensità di stimolazione è determinata dalla prestazione stessa del paziente durante l’esecuzione dell’esame. Queste procedure consentono di individuare i livelli di intensità necessari per ottenere punti prestabiliti della funzione di intelligibilità. Quando l’intensità dello stimolo viene diminuita dopo ogni risposta positiva e aumentata dopo ogni risposta negativa, la procedura viene definita «procedura adattiva semplice» (incremento e decremento dell’intensità per ogni risposta rispettivamente errata O corretta) e consente di identificare l’intensità corrispondente alla soglia di percezione (intelligibilità del 50%). Possono essere identificate anche le intensità corrispondenti ad altri punti della funzione attraverso l’utilizzo di «procedure adattive trasformate», che prevedono l’incremento e il decremento dell’intensità per sequenze di risposte g. 2).
La figura 3 mostra a titolo di esempio, una risposta tipica ottenuta con procedura adattiva semplice, in cui sono evidenti le caratteristiche escursioni derivanti dalla registrazione delle risposte corrette o errate. Per la corretta esecuzione del test occorre scegliere con cura il livello dell’intensità di partenza, la grandezza del gradiente (entità degli incrementi e decrementi di intensità) e la durata della prova (numero di items). Dato che tra la soglia ronale e soglia di percezione (intelligibilità del 50%) esiste una stretta correlazione, l’intensità di partenza, indicata dalla freccia nella figura, corrisponde alla soglia tonale media (500-1000-2000 Hz). La variazione di intensità o gradiente dovrebbe avere una dimensione confrontabile con la deviazione standard della soglia misurata con procedura adattiva; si ritiene conveniente utilizzare pertanto intervalli di variazione dell’intensità di 2 dB.
Per quanto riguarda il numero di items, si ritiene che si debbano utilizzare almeno 20 items.
La media delle mediane delle escursioni rappresenta l’intensità corrispondente alla soglia di percezione o intelligibilità del 50%; in tal modo si ottiene pertanto una valore medio della prestazione, con relativa deviazione standard, indicativa della variabilità statistica della misura.
in appendice viene riportato un modulo campione per la registrazione dei dati con una procedura adattiva.
AUDOMETRA VOCALE A SCELTA MULTIPLA
Per le prime 8 liste di parole bisillabiche per adulti (CD N.1) e per le prime 5 liste di fonemi (CD N. 4) sono stati preparati dei moduli, sia per il paziente che per l’operatore, in modo da poter utilizzare il materiale verbale registrato attraverso una modalità di somministrazione in scelta multipla (Closed-set; Volume III ,Audiometria Vocale Cutugno GN Resound 2000).
La somministrazione di test in modalità dosed-set è indicato per soggetti con ipoacusia grave che normalmente non consente livelli anche minimi di intelligibilità verbale in condizioni di scelta libera (open-set).
Quando si eseguono prove di audiometria vocale in closed-set si deve considerare il livello di risposta casuale, che corrisponde alla probabilità di risposte casualmente corrette (chance). Il livello di chance dipende dal numero di alternative: in caso di quattro alternative esso corrisponde al 25%, mentre in caso di tre alternative esso corrisponde al 33%. Al contrario, in caso di modalità di esecuzione in open-set, in cui le possibili alternative sono virtualmente infinite, il livello di chance tende a zero.
Per quanto riguarda le parole, il paziente deve indicare la parola stimolo tra quattro possibili alternative (chance=25%). In tal modo il compito è facilitato dal numero limitato di alternative.
Per quanto riguarda i fonemi, il paziente deve identificare il fonema «target» tra tre possibili alternative (chance=33%); sono stati individuati diversi livelli di difficoltà percettiva, sulla base della somiglianza fonemica delle alternative con il fonema stimolo.
LIVELLO I (massima difficoltà): la prima alternativa differisce solo per il tratto di sonorità; la seconda alternativa presenta uguale tratto di sonorità e massima somiglianza possibile del luogo di articolazione. La scelta quindi viene effettuata su fonemi simili per struttura dinamica e timbrica (pag. 21, VoI. III Audiometria Vocale Cutugno GN Resound 2000 ).
LIVELLO Il: le alternative hanno tratto di sonorità quando possibile uguale, e stesso luogo di articolazione; esse differiscono per modo di articolazione pag. 33, VoI, III Audiometria Vocale Cutugno GN Resound 2000).
LIVELLO III: le alternative sono uguali nel tratto di sonorità ed hanno lo stesso modo di articolazione; esse differiscono solo per luogo di articolazione, e quindi prevalentemente nella timbrica (pag. 45, VoI. III Audiometria Vocale Cutugno GN Resound 2000).
LIVELLO IV (minima difficoltà): le alternative differiscono dal fonema stimolo per tratto di sonorità, luogo e modo di articolazione c pag. Vol. III Audiometria Vocale Cutugno GN Resound 2000).
La posizione dello stimolo target rispetto alle alternative è stata randomizzata.
Il materiale di audiometria vocale infantile (parole mono-bi-tri-quadri-penta-sillabiche) può essere somministrato con modalità in closed set, mostrando al bambino le immagini corrispondenti alle parole che costituiscono le diverse liste. Vengono fornite 10 tavole, ciascuna contenente 20 immagini corrispondenti alle parole che compongono le 10 liste. Il bambino deve indicare l’immagine relativa allo stimolo acustico inviato (chance=5%).
Tecnica di audiometria vocale speciale
I test di Lafon si servono di parole la cui struttura e il cui significato interferiscono il meno possibile con la loro comprensione Klein AJ, 1978.
Gli elenchi detti di « prova cocleare» sono formati da dieci gruppi di 17 parole di tre fonemi. L’intensità della stimolazione è nettamente sopraliminare. Viene calcolato il numero di fonemi percepiti male per consentire di individuare le distorsioni di fonemi la cui origine è endococleare. Gli elenchi detti de «la prova di integrazione uditiva» raggruppano cinquanta parole che costituiscono dei gruppi che si differenziano tra loro solo per un fonema. Un errore di comprensione di questo fonema crea un’altra parola presente nello stesso elenco. Questo elenco permette di valutare le capacità di identificazione del messaggio.
L’ audiometria vocale in ambienti rumorosi permette di studiare la gravità dei disturbi di comprensione negli stessi ambienti rumorosi. Il principio del test consiste nel misurare la resistenza di questa comprensione aggiungendo all’ audiometria vocale convenzionale un rumore che maschera di intensità crescente. Dopo aver realizzato un’ audiometria vocale in campo libero, il livello di intensità della audiometria vocale viene fissato a 10 dB al di sopra del picco di comprensione ottenuto Elbaz P, 1992;
Viene aggiunto un rumore bianco che maschera con un’intensità iniziale di 5 dB al di sopra dell’intensità della audiometria vocale. Quindi, l’intensità del rumore bianco viene aumentata progressivamente di 5 in 5 dB. Per ogni intensità del rumore bianco, viene valutata la percentuale di parole correttamente ripetute. Diminuisce progressivamente mano a mano che l’intensità del rumore bianco aumenta (fig 4) . Può essere così valutata la resistenza di comprensione al rumore.

Fig .4 Esempio di curva dell’audiometria vocale in ambienti rumorosi disegnata secondo il protocollo di Elbaz et al. La comprensione diminuisce progressivamente mano a mano che l’intensità del rumore aumenta.
Risultati
L’ Audiometria vocale comune ha la funzione di controllare il valore di un audiogramma tonale, di valutare la ripercussione sociale di una sordità e di valutare l’efficacia di un apparecchio protesico.
Risultati in un soggetto normoudente
La curva dell’audiometria vocale ha, in un soggetto normale, una forma a «S» allungata (fig 1). La pendenza è più accentuata quando si utilizza un elenco di parole bisillabiche. Diversi punti importanti possono essere identificati:
la soglia di intelligibilità (sensitivity score): è l’intensità sonora a partire dalla quale il soggetto percepisce più del 50% delle parole. Nel soggetto normale, è uguale a 10 dB;
la massima di intelligibilità: è la percentuale massima di parole correttamente percepite. Nel soggetto normale, è uguale al 100%;
la percentuale di discriminazione: è la percentuale di parole comprese quando l’intensità è di 35 dB al di sopra della soglia di comprensione. Nel soggetto normale, è uguale al 100%.
Molti Autori insistono sul valore di soglia di intelligibilità quando si utilizzano degli elenchi bisillabici e della percentuale di discriminazione quando si utilizzano degli elenchi monosillabici.
Risultati in un soggetto ipoacusico
La curva dell’ Audiometria vocale non è deformata in caso di sordità di trasmissione: è semplicemente spostata verso destra, la soglia di intelligibilità si innalza. In caso di sordità di percezione, la comprensione può essere degradata. In alcuni casi, la curva audiometrica vocale assomiglia a quella della sordità di trasmissione: il massimo della comprensione non è diminuito, la soglia di intelligibilità si innalza. In altri casi, delle distorsioni sopraliminari (recruitment, diploacusia, squilibrio delle soglie uditive a bassa frequenza e ad alta frequenza) generano una deformazione della curva tipica delle sordità di percezione (fig 1).
AUDIOMETRIA VOCALE (II°APPROFONDIMENTO)
IMPIEGO DELL’AUDIOMETRIA VOCALE
Come si è detto l’impiego dell’audiometria vocale con finalità strettamente topodiagnostiche è attualmente limitato perché, in confronto, la combinazione di tecniche di audiometria obbiettiva (impedenzometria, otoemissioni, elettrofisiologiche) e di immagine ha dimostrato una sensibilità diagnostica nettamente superiore. Negli ultimi anni le applicazioni cliniche dell’audiometria vocale si sono progressivamente orientate da un lato verso la ricerca di stime globali della percezione del linguaggio, e dall’altro verso misure di aspetti specifici. Come esempi si possono ricordare le stime della «resistenza» della intelligibilità in varie condizioni di rumorosità ambientale, delle capacità di integrare i messaggi verbali con altre modalità sensoriali (labiolettura, vibrazioni tattili), della difficoltà percettiva nei confronti di specifici elementi costitutivi del linguaggio. Conseguentemente alla possibilità di indagare con maggior dettaglio differenti aspetti funzionali del sistema uditivo, si è anche verificarlo un utilizzo dell’audiometria vocale anche in aree cliniche connesse alla riabilitazione. In particolare, essa trova un utile impiego nelle «valutazioni pre-post» riguardanti gli impianti cocleari, l’adattamento protesico, gli interventi otochirurgici, la riabilitazione audio-foniatrica. L’estensione delle applicazioni, oltre alla necessità di disporre reattivi verbali ad hoc, ha talvolta modificato le stesse modalità di esecuzione dei test tradizionali. Come esempi si possono ricordare le procedure adattive (Levitt e Rabiner, 1967; Levitt, 1978; Turrini et AI, 1988) che in certe applicazioni possono sostituire il rilievo della tradizionale funzione di intelligibilità o la valutazione delle prestazioni in funzione delle modalità di risposta, se in «set aperto» o «set chiuso», o ancora l’utilizzo di modalità di risposta che permettono un’analisi degli errori per delimitare particolari debolezze nella percezione di specifici segmenti di linguaggio. La molteplicità degli impieghi dell’audiometria vocale e le attuali facilità offerte dalla tecnologia nella registrazione e controllo del materiale vocale può favorire la ricerca di reattivi e di metodologie di indagine abbastanza personali, allestiti cioè secondo le convinzioni del singolo utilizzatore e secondo le necessità dei pazienti cui dovranno essere applicati. Tale situazione, se da un lato possiede dei risvolti positivi, in quanto una più larga diffusione di queste tecniche può effettivamente facilitare la comprensione di molti aspetti della funzione uditiva, dall’altro presenta un lato negativo, poiché l’uso di reattivi molto differenti fra loro non consente di confrontare i dati raccolti in centri diversi. Per molte situazioni, come ad esempio la verifica su larga scala delle caratteristiche di un dispositivo protesico, solo la valutazione di una ampia base di dati, spesso di provenienza multi-centrica, permette di trarre conclusioni sufficientemente affidabili, a condizione, però, che i materiali utilizzati per i test siano costruiti secondo criteri omogenei. Allora, diventa indispensabile poter disporre di reattivi vocali il più possibile definibili o «misurabili», sia per le loro caratteristiche qualitative (i criteri seguiti nella scelta degli items), che quantitative (acusticamente calibrati secondo standard riconosciuti).
DESCRIZIONE DEI MATERALI
PAROLE BISILLABCHE PER ADULTI
Le liste di parole, proposte da Bocca e Pellegrini nel 1950, dimostrano alcuni limiti, legati soprattutto alla loro obsolescenza, e facilmente superabili ricorrendo a più moderni strumenti di analisi statistica del lessico. Infatti, quasi il 30% delle parole di queste liste supera la 100000° posizione dell’ordine di frequenza dell’italiano attuale, ed in particolare sono presenti alcune parole che risultano del tutto inconsuete (giunco, fiele, avo, gelsi, empio, gerla etc.). Sebbene il bilanciamento fonetico adottato da Bocca e Pellegrini risulti abbastanza rispettato, probabilmente è stato eseguito semplicemente sulla sillabazione ortografica, e non dopo una adeguata trascrizione fonetica. Di conseguenza sono state trascurate distinzioni importanti come, ad esempio, le differenze tra vocali aperte e chiuse (lEI e/e//, /O/ e /o/) o tra consonanti sorde e sonore fricative (IsI e /z/) ed affricate (ItsI e Idz/) e tra vocali e approssimanti (liI e IjI, luI eIw/). Si può ritenere che la composizione delle liste di parole per l’audiometria vocale sia migliorabile, individuando le parole attraverso la consultazione di vocabolari di occorrenza più aggiornati ed effettuando il bilancio sulle trascrizioni fonetiche del materiale selezionato.
I criteri nella scelta delle parole sono stati ricondotti ai seguenti parametri:
– alta occorrenza delle parole
– ridotta variabilità strutturale delle parole
– bilanciarnento fonetico complessivo sull’intero corpus
– bilanciamento fonetico tra le liste
La consultazione del più recente vocabolario di occorrenza (VELI, 1989) ha consentito di individuare sia le strutture fonologiche più ricorrenti sia le parole bisillabiche semanticamente più comuni. Il corpus di parole individuato è stato controllato e integrato attraverso la consultazione di un lessico di base (De Mauro, 1989), costituito dall’insieme di parole che formano il nucleo essenziale della lingua e che sono ritenute note a tutta la popolazione italiana, indipendentemente dal livello di istruzione. Sono stati utilizzati alcuni accorgimenti per la scelta delle parole allo scopo di rendere ancor più omogeneo il corpus. Di conseguenza sono state escluse dal corpus le parole aventi le seguenti caratteristiche:
– nomi propri
– preposizioni o comunque parole che è raro trovare isolate (fino, dello)
– parole che, pur essendo frequenti nel vocabolario di occorrenza, possiedono dubbia
frequenza di presenza nell’italiano parlato
– parole che presentano sensibili variazioni della pronuncia nelle varie forme di italiano regionale
– parole tronche (ovvero parole con accento che cade sull’ultima sillaba)
– verbi coniugati
Le 200 parole ottenute applicando i criteri sopra esposti sono state trascritte in notazione fonetica 1, allo scopo di quantificare il numero di occorrenze di ciascun fonema all’interno delle rispettive classi, vocaliche e consonantiche, Attraverso tale procedimento sulle parole di Bocca e Pellegrini, è stato quindi possibile eseguire un confronto tra i dati di frequenza del corpus da noi selezionato e quello proposto da Bocca e Pellegrini, avendo come riferimento i dati di Bortolini et Al (1978) relativi alla frequenza effettiva dei fonemi nella lingua italiana parlata.
1La trascrizione fonetica impiegata è stata proposta dal progetto ESPRIT n. 1541 (SAM 1988-89,) Multilingual Speech Input/Output Assessment, Methodology and Standardization. L’alfabeto che ne è derivato e che ha preso il nome di SAMPA [SAM (P)honetic (A)lphabet], ha lo scopo di consentire l’uso dei caratteri ASCII per la rappresentazione dei sim boli fonetici in processi automatici di trascrizione fonetica e in tutte le applicazioni in cui sia richiesta una standardizzazione dei simboli per la trascrizionefonetica di un testo ed è riconosciuto da tutte le associazioni europee di fonetica sperimentale (Gibbon et A., 1977).
TABELLA I. Simboli SAMPA utilizzati nella trascrizione fonologica; viene riportato anche il corrispondente simbolo secondo la trascrizione fonologica IPA SIMBOLI SAMPA
| SIMBOLO SAMPA |
DESCRIZIONE | CORRISPETTIVO IPA |
PAROLA (ESEMPIO) | TRAScRIzIoNE SAMPA |
|
| p | occlusi va bilabiale sorda | p | pane | “pane | |
| b | occlusi va bilabiale sonora | b | bara | “bara | |
| t | occlusiva dentale sorda | t | tana | “tana | |
| d | occlusi va dentale sonora | d | dado | “dado | |
| 1< | occlusi va velare sorda | k | cane | “kane | |
| g | occlusiva velare sonora | 9 | gatto | “gatto | |
| ts | affricata dentale sorda (intervocalica sempre lunga,) | ts | zitto azione |
“tsitto a”ttsjone |
|
| dz | affricata dentale sonora (intervocalica sempre lunga,) | dz | zona azoto | “dzOna a”ddzOto | |
| tS | Affricata palatale sorda | tJ | cena | “tSena | |
| dZ | Afri cata palatale sonora | d3 | gita | “dZita | |
| f | Fricativa labiodentale sorda | f | fame | “fame | |
| v | Fricativa labiodentale sonora | v | vano | “vano | |
| Fricativa alveolare sorda | 5 | sano | “sano | ||
| z | Fricativa alveolare sonora | z | sbaglio | “zbaLLo | |
| S | fricativa palatale sorda (intervocalica sempre lunga,) | J | scena, esce | “Sena, “ESSe |
|
| m | nasale bilabiale | m | mano | “mano | |
| n | nasale dentale | n | nano | “nano | |
| j | nasale palatale (‘intervocalica sempre lunga,) |
p | gnomo, bagno | “JOmo, “baJjo |
|
| r | liquida vibrante | r | rana | “rana | |
| I | liquida laterale | I | lana | “lana | |
| L | liquida palatale (intervocalica sempre lunga,) |
( | gli maglia |
Li “maLLa |
|
| j | semivocale palatale | j | ieri | “jEri | |
| w | semivocale labiovelare | w | uomo | “wOmo | |
| i | vocale anteriore alta | i | mite | “mite | |
| e | vocale anteriore medio-alta (chiusa,) | e | sera | “sera | |
| E | vocale anteriore medio-bassa (‘aperta) | E | meta | “mEta | |
| a | vocale centrale bassa | a | rata | “rata | |
| O | vocale posteriore medio-bassa (‘aperta,) | D | mora | “mOra | |
| o | vocale posteriore medio-alta (‘chiusa,) | o | voto | “voto | |
| U | vocale posteriore alta | U | muto | “muto | |
| “ | Accento lessicale primario | ‘ | |||
| C+C | consonante geminata (e lunga,) | vacca bagno | “vakka “baJJo |
In seguito, le 200 parole sono state distribuite in 10 liste costituite da 20 iterns, in relazione alla struttura fonologica. I diversi fonemi, vocalici e consonantici, sono stati ripartiti proporzionalmente in ogni lista, allo scopo di rendere le liste omogenee tra loro e comparabili per grado di difficoltà. In particolare, la ripartizione ha tenuto conto delle seguenti caratteristiche:
– numero di consonanti e vocali
– occorrenza di consonanti nasali
– occorrenza di consonanti fricative
– occorrenza di consonanti occlusive.
Inoltre, i fonemi labiali, labio-dentali e dentali sono stati equamente distribuiti in ciascuna lista, allo scopo di consentire l’utilizzo delle liste nella misura delle prestazioni con labiolettura.
Le possibili strutture delle parole bisillabiche nella lingua italiana sono prevedibili teoricamente sulla base di considerazioni fonologiche e fonotattiche, per ogni singola sillaba, e combinatorie tra le due sillabe. Da tale considerazione deriva un numero teorico di 24 strutture fonologiche, composte da un minimo di 2 a un massimo di 8 fonemi (tab. Il).
| STRUTTU RA |
(ESEMPIO) |
| VV CVV VCV CVCV VCCV VC:V CCVV CVCCV CCCVV CVC:V CCVCV VCCCV VC:CV CCCVCV CCVCCV CCVC:V CVCCCV CVC:CV CCCVC:V CCVCCCV CCVC:CV CCCVCCV CCCVC:CV CCCVCCCV |
(io)
|
Dalla consultazione delle prime 500 parole in ordine di frequenza decrescente del più recente lessico di occorrenza (VELI, 1989), sono stati selezionati 147 bisillabi, e successivamente classificati in relazione al tipo di struttura fonologica. Come si può notare, le strutture fonotattiche delle parole bisillabiche più familiari sono solo 16 e, tra queste, le prime sei comprendono ben l’83% dei bisillabi presenti nelle prime 500 parole più frequenti del lessico di occorrenza. Si è deciso quindi di selezionare, per la costituzione del corpus, solamente parole strutturare fonologicamente in accordo con le 6 sequenze più ricorrenti.
La tabella III riporta i valori percentuali di frequenza delle 6 strutture, relativamente a tutte le strutture fonologiche selezionate sulla terza riga, e i valori percentuali normalizzati alle frequenze delle prime 6 sequenze fonologiche sulla quarta riga. Sulla quinta riga è riportato il numero di parole per ogni gruppo selezionato in modo da rispettare correttamente le distribuzioni proporzionali all’interno di un corpus di 200 parole. Tale procedura consente di ottenere un corpus di parole molto omogeneo, sia per quanto riguarda la struttura stessa, sia per quanto riguarda la durata delle parole, essendo costituite da un minimo di 4 a un massimo di 6 fonemi. Sono quindi state scelte dal lessico di occorrenza le prime 200 parole bisillabiche in numero proporzionale alle percentuali relative alle strutture fonologiche. Inoltre sono state individuate le ulteriori 100 parole più frequenti allo scopo di creare una riserva, utile a rimpiazzare le parole che, nelle asi successive, potevano risultare inadatte. Durante la fase di scelta delle parole, è stato utilizzato, oltre al VELI, anche il lessico di base (De Mauro, 1989) che raccoglie parole di uso molto comune, costituenti il nucleo essenziale della lingua. Tale lessico, che dovrebbe essere noto a tutta la popolazione italofona adulta indipendentemente dal livello di istruzione, è stato utilizzato per integrare le eventuali carenze dei lessici di frequenza, ricavati prevalentemente da testi scritti. Il risultato finale riguardante la composizione del corpus delle parole è derivato da un progressivo aggiustamento delle proporzioni dei singoli fonemi, per ottenere la più stretta corrispondenza con i dati riportati da Bortolini et Al., (1978).
Per tale scopo, in alcuni casi si è resa necessaria la sostituzione di alcune parole con altre che, pur sempre di uso comune, erano di rango inferiore. La ripartizione complessiva dei fonemi in suoni vocalici e suoni consonantici (comprendenti le semivocali), è risultata rispettivamente del 41% (n=400) e 59% (n=576), in accordo con i dati riportati da Bortolini et Al (1978). Nella tabella IV sono riportati i valori delle frequenze di occorrenza calcolate separatamente per i totali parziali dei gruppi vocalici e consonantici (comprendenti le semivocali) dei singoli fonemi confrontati con i dati corrispondenti delle liste di Bocca e Pellegrini e della lingua italiana parlata (Bortolini et Al., 1978).
| CVCCV | CVCV | CVC:V | CCVCV | CCVCCV | CVCCCV | |
| PASTA | CASA | MASSA | PRIMO | GRANDE | SEMPRE | |
| 23 | 23 | 14 | 10 | 8 | 5 | % |
| 28 | 28 | 16 | 12 | 10 | 6 | % |
TABELLA III Valori percentuali e numero di parole delle 6 strutture fonotattiche selezionate
| VOCALI | NL % |
BP % |
BORTOLINIETAL % |
| a | 27 | 30.3 | 27.5 |
| e | 16.7 | 16.5 | 17 |
| E | 8.5 | 8.4 | 9.1 |
| 0 | 16.2 | 17.2 | 16 |
| 0 | 8 | 4.6 | 6.i |
| U | 4 | 48 | 2.9 |
| i | 19.5 | 17.2 | 21.2 |
| SEMI VOCALI | |||
| j | 3.4 | 4.2 | 2.7 |
| W | 1.7 | 1.5 | 1.6 |
| CONSONANTI | |||
| p | 5.7 | 5.5 | 5.2 |
| b | 1.9 | 1.6 | i.8 |
| T | 2.4 | i.6 | i.8 |
| V | 3.1 | 3.3 | 2.9 |
| t | 13.2 | 11.2 | 13.5 |
| d | 6.4 | 8.4 | 7.1 |
| ts | 1 | 0.2 | 1.2 |
| dz | 0.2 | 0.4 | 0.2 |
| S | 7.6 | 8.6 | 7.3 |
TABELLA IV. Frequenza di occorrenza di vocali e consonanti + semivocali nel gruppo di parole selezionato (NL) e in quello di Bocca e Pellegrini (BP), a confronto con i dati di Bortolini et Al (il numero in grassetto indica la migliore corrispondenza ai dati proposti da Bortolini et Al).
Rispetto alle proporzioni riportate da Bortolini et Al, le liste presentano una migliore corrispondenza per 22 fonemi, quelle di Bocca e Pellegrini solo per 6 fonemi e in 2 casi (/R/,/w/) si riscontrano differenze uguali. Per quanto riguarda il coefficiente di sonorità, nelle liste proposte si riscontra una percentuale del 40% di consonanti sor e, va ore c e si avvicina con migliore approssimazione ai dati di Bortolini et Al.
La comparazione delle distribuzioni del rango di occorrenza calcolate per le parole proposte (n=200) e quelle del lavoro di Bocca e Pellegrini (n=300) dimostra che il 50% e il 76% delle nuove parole proposte sono contenute entro il 1000° e 2000° rango, rispettivamente, mentre solo il 20.9% e il 29.5% delle parole di Bocca e Pellegrini occupano tale posizione nella lista di occorrenza. Inoltre, tutte le parole delle nostre liste fanno parte del lessico di base della lingua italiana proposto da De Mauro. Tali parole, anche se non vengono registrate da una statistica sulla lingua, di fatto sono psicologicamente disponibili e familiari a tutte le persone.
Per quanto riguarda le parole proposte da Bocca e Pellegrini, 38 non sono nemmeno riportate nel lessico di base di De Mauro.
La suddivisione in liste ha cercato di rispettare gli stessi criteri utilizzati per l’intero corpus. È stato scelto il numero minimo di 20 items per lista, al posto delle consuete 10 parole delle liste comunemente utilizzate nella pratica clinica, in quanto riteniamo che sia il numero minimo irrinunciabile per consentire un sufficiente bilanciamento. Ciascuna lista contiene 40 vocali e 56 (lista 9), 57 (liste 2 e 5) e 58 (liste 1, 3, 4, 6, 7, 8, 10) consonanti, distribuite con buona approssimazione in modo da rispettare in ogni lista le occorrenze dei diversi fonemi, come si può notare dalle tabelle V e VI.
Le consonanti occlusive variano da 18 a 24 per ciascuna lista, le fricative da 7 a 11, le nasali da 8 a 12.
Il numero di parole per ciascuna lista che iniziano con una consonante velare (IkI, IgI) varia da 2 a 5.
Particolare attenzione è stata posta nella ripartizione delle consonanti anteriori (bilabiali, labio-dentali, dentali, labio-velare) per consentire l’utilizzo delle liste nella valutazione delle capacità di labiolettura: nelle liste 1, 2, 3, 7, 10 sono presenti 48 consonanti articolate anteriormente, nelle restanti liste ne sono presenti 47.
TABELLA V Numero di vocali per ciascuna lista

TABELLA VI Numero di consonanti per ciascuna lista
OSSERVAZIONI
Le parole bisillabiche attualmente usate in audiometria vocale presentano, come è stato dimostrato, una serie di difetti, in parte legati all’annosità del materiale, per cui esso risente degli avvenuti cambiamenti della lingua, ed in parte ad un imperfetto bilanciamento fonemico. Infatti, anche se le frequenze di occorrenza dei singoli fonemi sono distribuite nell’intero corpus di parole con buona approssimazione relativa mente alla lingua parlata, le stesse frequenze non sono rispettate nella suddivisione in liste. In secondo luogo, una buona parte delle parole non rappresenta adeguatamente il lessico quotidiano, per quanto riguarda il rango di occorrenza. Da queste considerazioni è nata l’esigenza di individuare, nel rispetto dei principi delineati da Bocca e Pellegrini, un nuovo gruppo di parole che potesse essere utilizzato nelle prove di audiornetria vocale con maggiore affidabilità.
Il numero elevato di parole che costituiscono il corpus è necessario per eliminare l’influenza della memoria: le parole devono essere perciò diverse in ciascuna lista, perché potrebbero essere ricordate dal soggetto in esame, se ascoltate ripetutamente, a causa del loro contenuto semantico. Il corpus di parole è stato suddiviso in liste seguendo dei criteri che possano consentire una stabilità statistica dei risultati indipendentemente dalla lista utilizzata. Questo implica una assoluta intercambiabilità delle liste, cioè ogni lista possiede le stesse proprietà in qualsiasi condizione. Per tale scopo, le liste sono state bilanciate tra loro sia per l’occorrenza di ciascun fonema, sia per la struttura fonologica delle parole.
È stata mantenuta anche una buona corrispondenza tra l’occorrenza dei fonemi nelle liste con l’occorrenza nella lingua parlata (bilanciamento fonetico). La necessità di utilizzare nei test di audiometria vocale un materiale foneticamente bilanciato, che presenti cioè le stesse frequenze relative della lingua parlata per ciascun fonema, è giustificata dalla considerazione che, quando un particolare soggetto non riuscisse a percepire un fonema presente raramente nella lingua parlata, si potrebbe ottenere una misura del suo handicap superiore alla realtà, se il materiale non fosse bilanciato, Tuttavia il bilanciamento fonetico non riveste una grande importanza sotto questo aspetto, almeno per quanto riguarda le parole e le frasi, perché ie regole d coarticolazione, ma soprattutto il contenuto semantico ne riducono la rilevanza in relazione agli scopi diagnostici e di valutazione delle capacità comunicative. In ogni caso, abbiamo voluto mantenere questa caratteristica, poiché riteniamo che il bilanciamento fonetico, in particolare un bilanciamento tra le liste, possa contribuire ad aumentare l’omogeneità del materiale.
Un altro parametro molto importante per garantire una buona equipollenza delle liste e una corretta interpretazione dei risultati, riguarda la selezione delle parole in relazione alla loro familiarità (Owens, 1961; Epstein etAl, 1968). Schultz (1964) notò che il 14% degli errori commessi nelle prove con le liste CD W-22 erano relativi al 5% delle parole a bassa occorrenza.
Il corpus proposto è composto da parole sicuramente familiari a qualunque persona adulta italofona, indipendentemente dal grado di istruzione e cultura, contribuendo ad aumentare l’intercambiabilità delle liste e a diminuire la variabilità interindividuale non legata a problemi uditivi.
Le liste sono composte da 20 iterns ciascuna, perché tale numero rappresenta nella nostra opinione il numero minimo necessario per consentire un adeguato bilanciamento fonetico tra le liste e il giusto compromesso tra durata dell’esame e validità statistica dei risultati.
FRASI PER ADULTI
Anche per questo tipo di reattivo verbale si pone il problema di rinnovare il materiale, per renderlo più rispondente alle caratteristiche attuali della lingua parlata, sia dal punto di vista sintattico, che per la fruibilità degli elementi lessicali.
Il materiale è costituito da 200 frasi ripartite in 10 liste di 20 frasi ciascuna.
Nella costituzione delle frasi sono stati adottati alcuni criteri nella scelta degli elementi lessicali, delle strutture morfosintattiche e dell’ordine dei costituenti frasali, allo scopo di rendere le proposizioni semplici e facilmente comprensibili ad un pubblico di soggetti molto eterogeneo per età, provenienza regionale e livello culturale.
LESSICO
Si è fatta attenzione ad evitare in gran parte le parole che potessero risultare in qualche modo di difficile comprensione, sia isolate che in contesto di frase: i termini astratti (es: solitudine, altezza, varietà…), gli usi metaforici o con sfumature di significato (es: essere in corsa per qualcosa, dar retta, dar ascolto…), le parole poco comuni (es: eterogeneo, supportare, plausibile ..), etc. In generale i termini sono stati scelti in maggioranza tra le parole del vocabolario fondamentale (cfr. De Mauro, 1989: 106 «parole di massima frequenza nel parlare e nello scrivere e disponibili a chiunque in ogni momento») e, in seconda scelta, nel vocabolario di alto uso (l’insieme delle parole di maggior uso) e in quello di massima disponibilità (l’insieme delle parole che si usano raramente, ma legate ad oggetti, fatti, esperienze comuni della vita quotidiana, es: forchetta, tubo).
E stata poi considerata, accanto alla facilità dei singoli termini lessicali, la plausibilità del legame semantico degli elementi interni alla proposizione. al fine di ottenere frasi massimamente naturali.
Inoltre sono state inserite nelle frasi 100 parole facenti parte delle liste di bisillabi per
l’audiometria vocale (Turrini et Al, 1993); queste costituiscono un sottogruppo utilizzabile per una valutazione comparata di parole isolate e parole in contesto.
MORFOSI NTASSI
La morfologia costituisce il settore di maggiore difficoltà nella produzione e percezione da parte di soggetti ipoacusici, a causa dell’esiguità del corpo fonico e dello scarso valore semantico (Simone, 1988).
Allo scopo di ridurre la presenza, all’interno delle frasi, di elementi generalmente atoni e perciò scarsamente percepibili (come i pronomi riflessivi, impersonali, etc.) non sono state introdotte costruzioni passive, riflessive e impersonali. Le stesse risultano particolarmente difficili da comprendere, anche considerando esclusiva- mente la loro struttura sintattico-semantica. Naturalmente non è stato possibile evitare elementi clitici (atoni) come gli articoli e le preposizioni articolate e non.
Nella scelta dei tempi verbali è stata considerata tanto la loro frequenza d’uso nell’italiano contemporaneo (Voghera, 1992; Simone, 1993), quanto la loro struttura morfofonologica in relazione a criteri di percepibilità. Pertanto compaiono come tempi verbali, in ordine decrescente di frequenza: presente, passato prossimo, imperfetto, futuro, passato remoto. Per quel che riguarda i modi verbali, è stato adottato esclusivamente l’indicativo.
La scelta della struttura sintattica delle frasi è stata operata seguendo il più possibile criteri di frequenza d’uso (Voghera 1992), fatte salve le restrizioni, di cui già si è detto sopra, circa le strutture passive, riflessive e impersonali. Riguardo alla modalità si tratta sempre di frasi dichiarative semplici e indipendenti; non sono state incluse cioè strutture complesse costituite da principale + subordinata o relativa. Anche per la scelta dei complementi e degli avverbi, si è cercato di seguire un criterio di frequenza.
ORDINE DEI COSTITUENTI
È stato privilegiato grosso modo un ordine dei costituenti con il soggetto che precede il verbo (SV = Soggetto+Verbo, SVPN = Soggetto+V+predicato nominale) e il verbo che precede l’oggetto (VO = Verbo+Oggetto) o i suoi modificatori (VC = Verbo+complemento, VX. = Verbo +elemento avverbiale).
Inoltre sono state introdotte alcune strutture sintattiche che presentano in posizione iniziale di frase un elemento X che precede il verbo:
XVC = elemento avverbiale +Verbo+ complemento,
XVO = elemento avverbiale o complemento +Verbo + oggetto).
Tali strutture non manifestano necessariamente un ordine marcato, se non accompagnate da un profilo intonativo che marchi l’elemento iniziale. Le frasi sono state perciò realizzate, nei limiti del possibile, in fase di registrazione, con un’intonazione dichiarativa piana, senza cioè porre alcuna enfasi sull’elemento iniziale.
La presenza di frasi strutturalmente simili, ma con ordine dei costituenti diverso è stata bilanciata tra le diverse liste di frasi.
LUNGHEZZA
Le frasi sono costituite da un numero di sillabe compreso tra 9 e 13. Si tratta perciò di frasi brevi e, dal punto di vista prosodico, comprese in un’unica unità di emissione (o gruppo tonale).
Il materiale è stato raccolto in un database nel quale sono state riportate le seguenti informazioni:
1. testo della frase;
2. tipo sintattico (SVO, SVC, SPN, SVX, VO, XVO, VC, XVC, VOI, SVOI);
O S = soggetto
O V = verbo
O O = oggetto
O C complemento
O PN = predicato nominale
O X. = elemento avverbiale
O I = indice di valenza argomentale del verbo (I = verbo intransitivo ad un
argomento, soggetto; TI = verbo transitivo a 2 argomenti, soggetto e oggetto diretto; III = verbo transitivo a 3 argomenti, soggetto, oggetto diretto e oggetto indiretto);
3. Tempo verbale: presente (pre), passato prossimo (pp), imperfetto (imp), futuro
(fut), passato remoto (pr)
4. presenza e tipo di complemento (oggetto, luogo, tempo, modo, altro)
5. presenza e tipo di avverbio (luogo, tempo, modo, altro)
6. numero di sillabe
ARRANGIAMENTO IN LISTE
I criteri scelti per la costruzione delle frasi e l’analisi statistica descritti nei paragrafi precedenti hanno consentito di organizzare dieci liste, equivalenti tra loro per i parametri considerati, ciascuna contenente venti frasi.
Ogni lista contiene 20 frasi ripartite sulla base della struttura sintattica; in tal modo è stato possibile controllare anche il parametro della lunghezza (numero di sillabe).
In conclusione, ciascuna lista presenta lo stesso numero di frasi con la medesima struttura sintattica, come segue:
5 SVO (Soggetto, Verbo e complemento oggetto, più eventuali altri elementi facoltativi,)es: il cantante ha una bella voce;
4 SVC (Soggetto, Verbo e un Complemento – luogo, modo, tempo, altro – più eventuali altri elementi facoltativi,)
es: il sentiero passa per il giardino;
3 SPN (‘Soggetto, Verbo essere e predicato nominale, più eventuali altri elementi facoltativi,)es: il fritto misto è pesante;
2 SVX (Soggetto e Verbo – seguiti da altri elementi facoltativi,)es: l’infermiera viene ogni giorno;
1 VO (Verbo e complemento oggetto – più altri elementi facoltativi,)es: prepariamo la colazione alla mamma;
1 XVO (Verbo e complemento oggetto – preceduti da altri elementi facoltativi,)es: ieri hai comprato poco latte;
1 VC (Verbo e un complemento – luogo, modo, tempo, altro più altri elementi facoltativi)es: guideremo solo in autostrada;
1 XVC (Verbo e un conzplemento – luogo, modo, tempo, altro – preceduti da altri elementi facoltativi) es: domani andrò da mia madre;
1 (S) VOI (Soggetto facoltativo, Verbo, complemento oggetto, complemento Indiretto,)es: Laura insegnava inglese ai bambini o leggeva le favole ai bambini;
una ripetizione aggiuntiva a caso di uno dei seguenti tipi: SVO, 5VC, SPN, VO, XVO, VC, XVC.
Gli elementi facoltativi possono essere: avverbi – di tempo, luogo, modo o altro; aggettivi.
TABELLA VII. Riepilogo della struttura delle frasi e conteggio degli elementi presenti.
L’elemento X che precede i costituenti principali nelle frasi XVC è un elemento avverbiale. L’elemento X che precede i costituenti principali nelle frasi XVO può essere un elemento avverbiale o un altro complemento diverso dall’oggetto. In entrambi i casi la presenza di X serve a segnalare che il verbo, a differenza delle corrispondenti frasi VC e VO, non occupa la prima posizione. L’elemento X che segue i costituenti principali nelle frasi SVX è un elemento avverbiale che svolge essenzialmente una funzione riempitiva.
L’ordine delle frasi all’interno di ciascuna lista è stato randomizzato.
Definizione
Test di valutazione della funzionalità uditiva utilizzando lo stimolo verbale
Utilità
L’audiometria vocale può essere utilizzata come test diagnostico, come test di audiometria protesica, come test di valutazione medico legale. L’audiometria vocale può essere utilizzata come test diagnostico, come test di audiometria protesica,( rappresenta un esame utile per la predizione del risultato funzionale degli apparecchi acustici ),come test di valutazione medico legale. Il materiale vocale può essere preregistrato o recitato in viva voce (acumetria vocale). Il paziente può identificare lo stimolo verbale all’interno di una lista chiusa (test di identificazione), oppure ripetere ciò che ha sentito (test di riconoscimento). La velocità di ripetizione è libera con il materiale preregistrato oppure, la più veloce possibile nel test Speech Tracking. Lo Speech tracking viene eseguito in quattro modalità, con e senza l’ausilio della lettura labiale e con e senza rumore. Può essere utilizzato come test di audiometria vocale diagnostica e come test di audiometria protesica. Lo Speech tracking utilizzato come strumento di follow up permette di costruire dei grafici di performance riabilitativa dove è possibile identificare sia il momento di chiusura del gap, quando possibile, nonché il momento di plateau in cui concludere la riabilitazione. I risultati possono essere riportati su grafici, oppure numericamente.
• ALLESTIMENTO DEL MATERIALE
MATERIALE FONETICO
Generalità
Per eseguire una audiometria vocale il materiale deve avere alcune caratteristiche particolari:
– composizione fonetica tipica della lingua in cui si effettua l’esame,
– deve essere foneticamente bilanciato
– semplice,
– familiare e di uso comune.
Contenuto
Nello stesso modo in cui la lettera è l’elemento più piccolo del linguaggio scritto, l’unità significativa più piccola del linguaggio parlato è il “fonema”. Nella lingua italiana, possiamo distinguere i fonemi vocalici (i-è-e-a-ò-ou) ed i fonemi consonantici tra cui quelli occlusivi (p-b-m-n-t-d-n-gn-gh-n), semi-occlusivi (z-ci-gi) e costrittivi (f-v-s-s-sc-r-I-gli).
La Figura 5 dimostra le componenti frequenziali dei suoni della lingua italiana in funzione dell’ampiezza e della frequenza. Anche se la percezione del linguaggio dipende da una immagine uditiva tridimensionale (ampiezza vs frequenza vs tempo) questa rappresentazione dà una idea abbastanza chiara delle caratteristiche a breve termine del linguaggio parlato.
Il materiale fonetico adoperato per le tecniche di audiometria vocale dovrebbe avere un contenuto equilibrato di fonemi e, inoltre, dovrebbe corrispondere ai seguenti criteri:
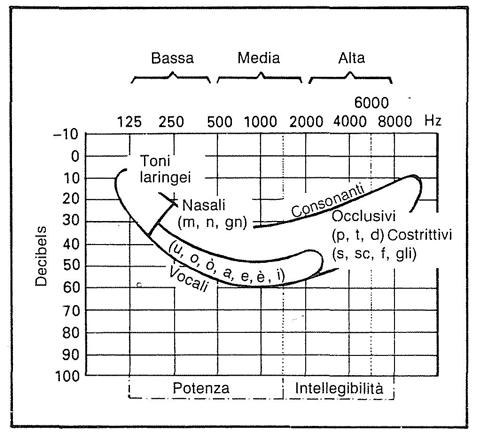
Fig. 5 Componenti frequenziali della lingua italiana.
– i singoli fonemi dovrebbero essere presenti nel materiale verbale con la stessa relativa frequenza con la quale compaiono nel linguaggio parlato comune;
– il contenuto fonetico deve essere rappresentativo del linguaggio in cui vengono effettuate le prove;
– le parole devono essere di uso comune (familiarità);
– la difficoltà media deve essere uguale per tutte le parole e per tutte le frasi facenti parte delle singole liste.
Liste
In Italia, il materiale verbale usato più frequentemente nell’audiometria vocale comprendeva:
– Frasi normali a senso compiuto (Bocca 1950)
– Parole bisillabiche a senso compiuto (Bocca e Pellegrini 1950)
– Logotomi con costruzione Consonante-Vocale-Consonante-Vocale (CVCV) senza senso compiuto (Azzi1950)
E’ stato sostituito da:
-
Audiometria vocale (Cutugno et Al nel 2000)
LE LISTE USATE PER LE PROVE SENSIBILIZZATE E/O PER LE PROVE SPECIALI COMPRENDONO:
– Frasi sintetiche – senza significato, ma sintatticamente corrette (Antonelli, Barocci e Mantovani)
– SPIN test versione italiana (De Seta, Ballantyne)
– Parole bisillabiche (test di Katz)
– Parole bisillabiche con/senza immagini per bambini (3-6 anni)
– Frasi normali per bambini (3-6 anni)
– Frasi normali e sintetiche (da fiaba popolare) per bambini (età scolare)
– Batteria di prove per le minime capacità uditive (Prosser e Arslan)
Tutto il materiale fonetico menzionato in questo capitolo è riportato per esteso nella Appendice B.
Nei paesi anglosassoni, fanno uso di materiale basato per lo più sulle parole monosillabiche tra cui:
– PAL PB 50 monosillabe a senso compiuto
– Fry – monosillabe CVC
– Manchester .Junior (MJ) test – monosillabe a senso compiuto, adatto per bambini <6 anni
– Test rimata di Reed – illustrazioni e parole rimate per bambini <5 anni (a scelta multipla)
– Manchester Picture (MP) test – identificazione con immagini
Tuttavia, questo tipo di materiale non è adatto alla nostra lingua in quanto non esistono abbastanza parole monosillabiche significative per comporre delle liste intere con un bilanciamento adeguato.
• MATERIALI
I materiali vocali pre-registrati possono essere classificati secondo le loro caratteristiche di ridondanza fonetica, sintattica e semantica per cui si distinguono in:
• logotomi,
• parole bisillabiche
• frasi sintetiche
• frasi normali.

Fig 6: Caratteristiche linguistiche dei materiali vocali
Il materiale utilizzato in viva voce per lo Speech Tracking è tratto da comuni testi scritti scelti in base all’età del paziente e classificati in base alla difficoltà del testo. Si identificano così i seguenti livelli:
• Livello -1: materiale costituito da singole parole bisillabiche e trisillabiche di uso comune e può essere proposto in due modalità:
livello -1a in lista aperta (la prova viene proposta senza alcun riferimento sull’argomento);
livello -1b in lista chiusa (le parole vengono scelte all’interno di una categoria).
• Livello 0: materiale costituto da un breve racconto strutturato in frasi semplici, composte da parole familiari.
• Livello +1: materiale costituito da racconti in cui sono inseriti dialoghi a discorso diretto.
• Livello +2: materiale costituito da un brano di narrativa per ragazzi.
• Livello +3: materiale tratto da un quotidiano.
Come competizione possono essere utilizzati: rumore rosa pulsato ogni tre secondi, caffetteria noise, discorso continuo. Infine lo Speech tracking viene eseguito in quattro modalità, con e senza l’ausilio della lettura labiale e con e senza rumore. Può essere utilizzato come test di audiometria vocale diagnostica e come test di audiometria protesica.
Come test diagnostico si considerano i valori assoluti delle prove ed un gap tra i risultati in lettura labiale e quelli ottenuti in bocca schermata permettono di confermare che la competenza “cognitiva” è conservata e che le difficoltà lamentate sono legate solo ad un deficit uditivo. Utilizzando poi lo stesso test con protesi è possibile verificare l’efficacia dell’ausilio sulla più o meno completa chiusura del suddetto gap, permettendo poi dei rapidi paragoni tra le diverse soluzioni protesiche o le diverse mappe cocleari.
RISPOSTA RICHIESTA AL PAZIENTE
Il paziente può identificare lo stimolo verbale all’interno di una lista chiu sa (test di identificazione), oppure ripetere ciò che ha sentito (test di riconoscimento). La velocità di ripetizione è libera con il materiale preregi strato oppure, la più veloce possibile nel test Speech Tracking.
È importante ricordare che nello Speech Tracking il paziente non deve capire il significato delle parole, ma solo ripeterle. Si tratta quindi di un test di riconoscimento.
Con i materiali preregistrati, si inviano blocchi di dieci items recitati uno per volta del materiale scelto:
-
ad intensità decrescenti con intervalli di 10 dB,
-
oppure ai vari rapporti S/R, quando l’intensità del messaggio pri mario è mantenuta fissa
e le risposte corrette ripetute o identificate dal paziente vengono calcola te percentualmente nel range che va dal 100 % allo 0%.
Nello Speech Tracking si contano invece il numero di parole corretta mente ripetute in un minuto (P.A.M. parole al minuto) nelle quattro moda lità di somministrazione e cioè:
-
Lettura labiale in quiete (LLQ)
-
Lettura labiale nel rumore (LLR)
-
Bocca schermata in quiete (BSQ)
-
Bocca schermata nel rumore (BSR).
REPORT DEI RISULTATI
I risultati possono essere riportati su grafici, oppure numericamente. In audiometria vocale diagnostica con materiale preregistrato trasmesso in cuffia o per via ossea a intensità decrescenti, si costruisce la curva di articolazione vocale all’interno di un grafico che vede sull’asse delle ascisse i decibel e sull’asse delle ordinate la percentuale di risposta. In base alla topodiagnosi si ottengono dei profili caratteristici per le ipoa cusia trasmissive, quelle cocleari e quelle retro cocleari.
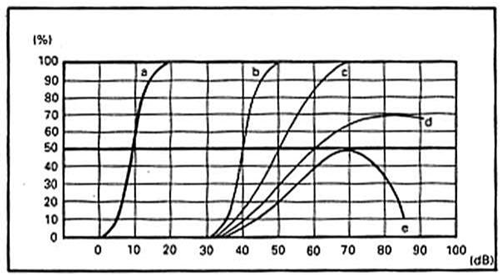
Fig. 7: Profili di audiometria vocale diagnostica nella normoacusia (a), nell’ipoacusia trasmissiva (b), nell’ipoacusia mista (c), nell’ipoacusia percettiva cocleare (d) e nell’ipoacusia percettiva retro cocleare (e).
In audiometria protesica in campo libero con intensità del messaggio pri-mario fissa e variando la competizione, i risultati vengono riportati su un grafico dove sulle ordinate si mantengono le percentuali di risposte corrette, mentre sulle ascisse si riportano i vari S/R. All’interno del grafico si identificano due aree principali nelle prove con protesi e cioè il guadagno funzionale ed il deficit residuo.
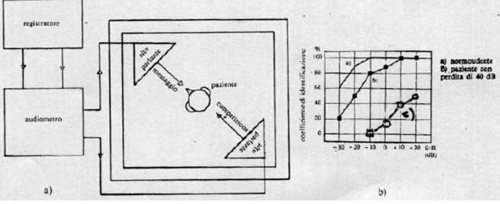
Fig .8: Modalità di esecuzione del test di controllo protesico in campo libero e grafico del risultato (a=normoudente; b= con protesi; c= senza protesi). L’area compresa tra C e B rappresenta il guadagno funzionale. L’area compresa tra B e A rappresenta il deficit residuo
Infine lo Speech tracking viene eseguito in quattro modalità, con e senza l’ausilio della lettura labiale e con e senza rumore. Può essere utilizzato come test di audiometria vocale diagnostica e come test di audiometria protesica.
Come test diagnostico si considerano i valori assoluti delle prove ed un gap tra i risultati in lettura labiale e quelli ottenuti in bocca schermata per mettono di confermare che la competenza “cognitiva” è conservata e che le difficoltà lamentate sono legate solo ad un deficit uditivo. Utilizzando poi lo stesso test con protesi è possibile verificare l’efficacia dell’ausilio sulla più o meno completa chiusura del suddetto gap, permettendo poi dei rapidi paragoni tra le diverse soluzioni protesiche o le diverse mappe cocleari.
Sempre lo Speech tracking utilizzato come strumento di follow up per mette di costruire dei grafici di performance riabilitativa dove è possibile identificare sia il momento di chiusura del gap, quando possibile, nonché il momento di plateau in cui concludere la riabilitazione.

Fig. 9: Follow up con lo speech tracking nelle quattro modalità di somministrazione. Si noti la chiusura del gap tra performance in lettura labiale e bocca schermata, a con ferma dell’efficacia del trattamento riabilitativo, nonché il momento di conclusione dello stesso
Test con frasi
La capacità di discriminazione vocale può essere valutata utilizzando delle frasi allo stesso modo delle parole monosillabiche. Fletcher e Steinberg (1930) hanno costruito una lista di intelligibilità per frasi al BTL, Questa è formata da 5 liste di 50 frasi strutturate come semplici frasi interrogative o imperative. Egan (1948) e Hirsh (1952) formularono due critiche sostanziali alle frasi del BTL. Le domande spesso richiedevano una conoscenza specifica dell’area intorno la città di New York e molte voci erano particolarmente difficili e superavano le capacità di molte persone di rispondere correttamente. Perciò non si rivelarono clinicamente utili come anticipato in precedenza (Hirsh, 1952). Il PAL Auditory Test n. 12 (Hudgins e coll., 1947), benché ideato per determinare la soglia vocale con frasi, può essere adattato come test di discriminazione vocale. Offre il vantaggio di richiedere poche informazioni specifiche e alle frasi si può rispondere con una sola risposta. La maggior parte delle frasi è così facile che un elevato livello intellettuale non è un requisito indispensabile.
Al CID è stato sviluppato un set di frasi quotidiane (Davis e Silverman, 1978) che consiste di 10 liste di 10 frasi con 50 parole chiave contenute in ciascun set. Sono state utilizzate delle frasi interrogative, dichiarative e imperative e il punteggio è basato sul numero di parole chiave identificato.
Un approccio unico all’utilizzo di materiale con frasi è stato avanzato da Speaks e Jerger (1965) con l’introduzione del Synthetic Sentence Identification Test (SSI). Il materiale del test non è in realtà costituito da frasi dato che le parole utilizzate non formano frasi di senso compiuto ma si avvicinano a delle frasi reali. Le parole utilizzate per formulare le frasi sintetiche sono state selezionate seguendo delle regole sintattiche precise. Il SSI utilizza un formato chiuso ed ha avuto larga diffusione clinica. Dubno e Dirks (1983) hanno proposto alcuni suggerimenti per ottimizzare l’affidabilità del SSI. Kalikow e coli. (1977) hanno sviluppato un test di frasi a risposta aperta chiamato «speech perception in noise test» (SPIN). E formato da Otto gruppi di 50 frasi. Metà delle frasi contengono delle parole ad alta predicibilità e metà a bassa, basata sul contesto, sulla sintassi e sulla prosodia. Il punteggio è basato sull’identificazione corretta delle parole chiave. Il rumore di sottofondo consiste nelle voci sovrapposte di 12 locutori.
FATTORI CHE INFLUENZANO I VALORI Dl DISCRIMINAZIONE VOCALE
I fattori che influenzano la discriminazione vocale sono numerosi. Ci sono fattori fisici correlati allo stimolo usato (per es. il livello di presentazione, la composizione in frequenza, la distorsione, il rapporto segnale-rumore e la durata). Secondo, vi sono fattori che sono di natura linguistica. I più importanti di questi sono l’articolazione, il dialetto, il contesto, la ridondanza e la familiarità del paziente sono le parole utilizzate. Terzo, vi sono delle variabili legate alle procedure che possono causare degli effetti indesiderati. Da questo punto di vista bisogna considerare la modalità e la frequenza di presentazione, la modalità di risposta, la modalità di attribuzione del punteggio, il materiale utilizzato, le differenze tra speaker e speaker e una serie di variabili correlate al paziente che comprendono l’ipoacusia, la motivazione, l’esperienza, l’intelligenza, l’istruzione e il grado di cooperazione. Questi esempi certamente non costituiscono la lista completa delle variabili in gioco ma servono a ricordare al lettore la complessità di una prova apparentemente semplice e la necessità di controlli adeguati per essere sicuri dell’affidabilità dei risultati. Alcuni di questi fattori potrebbero essere più appropriatamente discussi in più paragrafi, alcuni sono tra loro intimamente correlati. Tranne poche eccezioni le alterazioni di performance attribuibili a tali variabili comporteranno una riduzione del punteggio di discriminazione vocale piuttosto che un suo aumento. Chiaramente è relativamente facile far scadere la performance vocale ma non altrettanto aumentarla. A volte però si possono anche incontrare dei punteggi elevati. Tali punteggi elevati possono aversi per errori procedurali (per es. permettere la visione al paziente durante l’invio degli stimoli vocali), errori nel calcolo dei punteggi o deficit di mascheramento dell’orecchio non in esame.
Livello di presentazione
Gli effetti del livello di presentazione nella comprensione di diversi stimoli vocali possono essere facilmente visualizzati utilizzando la funzione performance-intensità (PI) descritta in precedenza. La Figura 10 tratta da Davis e Silverman (1960), illustra le funzioni PI di soggetti normoacusici per le parole spondee, i monosillabi CID W-22 e PAL B-50. Accanto è tracciata anche una funzione anomala di performance-intensità. Si può notare che il 50% di identificazioni corrette si ottiene a livelli di più bassa pressione sonora in SPL con le parole spondee (20 dB SPL) piuttosto che con i monosillabi registrati del CID W-22 (27 dB SPL) o con i monosillabi registrati del PAL PB-50 (33 dB SPL). La ripidità delle funzioni PI è anche variabile mostrando un maggiore aumento nella percentuale di identificazione corretta al variare dell’intensità con gli spondei rispetto ai monosillabi. La terza caratteristica importante è che con le parole spondee e i monosillabi CID W-22 il 100% di identificazione corretta si Ottiene alla fine quando viene aumentato il livello di presentazione, mentre con i monosillabi PAL PB-50 si ottiene un picco massimo del 92% a prescindere dall’intensità del livello di presentazione del materiale vocale. Per ciascuno di questi materiali in persone normoacusiche i punteggi rimarranno a livelli massimi con successivi aumenti del livello di presentazione. In certe condizioni patologiche l’aumento dell’intensità di presentazione sopra il livello in cui si ottiene lo score massimo comporta una notevole diminuzione della discriminazione vocale. Questa diminuzione della performance è stata chiamata «rollover» ed è stata dimostrata essere diagnosticamente utile (Jerger e Jerger, 1971; Dirks e coll., 1977; Bess e coll., 1979; Shirinian e Arnst, 1980).

Fig.10 Funzioni di articolazione di Rush Hughes, test W 22 e con spondei È dimostrata inoltre la funzione di articolazione ottenuta da alcuni orecchi patologici Notare che la curva passa attraverso un massimo e quindi declina con un aumento dl intensità Sono illustrate le soglie di detenzione e di intelligibilità per le parole spondaiche, (Modificato da Davis e Silverman (1960) by Goetzinger. C P. 1972. Word discrimination testing in J. Katz, ed. Handbook of Clinical Audiology. Williams & Wilkins, Baltimore).
Rapporto segnale-rumore e tipi di rumore competitivo
In generale, l’intelligibilità del materiale vocale si situa lungo un continuum di difficoltà dovute alle informazioni dotate di significato del messaggio. Più è ricco il messaggio e più è ripida la funzione PI. Parole a quattro sillabe sono più intellegibili delle parole con tre sillabe e parole con tre sillabe sono più intellegibili di quelle a due sillabe e così via. Le parole monosillabiche possiedono un grado di intelligibilità maggiore rispetto alle sillabe senza senso e le frasi sono più intellegibili rispetto alle parole polisillabiche. Il numero di suoni in una parola, così come il numero delle sillabe è in grado di influenzare l’intelligibilità vocale (Egan, 1948; Miller e colI., 1951; Hirsh e coll., 1954). Un funzione PI per parole monosillabiche diventerà più ripida quando le stesse parole vengono udite all’interno di frasi (Miller e coll., 1951). Questi stessi ricercatori hanno dimostrato che la funzione PI varia in base al rapporto segnale-rumore. Le variazioni che si hanno a causa della presenza di un rumore sono influenzate anche dal tipo di ipoacusia. Se il segnale diventa sfavorevole rispetto al rumore gli effetti sui punteggi di discriminazione vocale sono più pronunciati per i soggetti con ipoacusia neurosensoriale che per i soggetti normoacusici (Olsen e Tillman, 1968). E non soltanto il rapporto segnale-
rumore costituirà un fattore di variabilità ma anche il tipo di rumore mascherante utilizzato è in grado di influenzare la performance (Lovrinic e colI., 1968; Williams e Hecker, 1968; Garstecki e Mulac, 1974). Lovrinic e coll. (1968) hanno comparato la performance di un singolo gruppo di soggetti in cinque misure di discriminazione vocale. Benché il vocabolario delle liste CID W-22 utilizzato in questo studio, sia noto per essere ben omogeneo rispetto al parametro difficoltà (Elpern, 1960; Ross e Huntington, 1962) furono riscontrate grosse differenze nei punteggi medi per il materiale presentato in presenza di un rumore mascherante di + 12 dB di rapporto segnale-rumore (il materiale vocale era 12 dB più alto del rumore). Lovrinic e coil. hanno osservato non solo delle performance peggiori ma anche un’assenza di prove facili, in presenza di rumore ipsilaterale (per es. un sottofondo di più voci). Loven e Hawkins (1983) hanno anch’essi riportato che liste presentate in presenza di rumore non si equivalevano.
Findlay (1976) ha comparato la performance di soggetti giovani di sesso maschile normoacusici con quella di soggetti con ipoacusia indotta dal rumore in una serie di compiti uditivi. Fra questi vi era anche la discriminazione vocale in presenza di un rumore a spettro vocale e un rumore tipo cocktail party (cioè con 6 parlatori diversi). In tali condizioni i punteggi di discriminazione vocale erano più scadenti per i soggetti con ipoacusia, però fu notata una diversità maggiore in performance tra i due gruppi con il materiale CID W-22 quando era presentato con rumore tipo cocktail party. Il riscontro di peggiori discriminazioni vocali in condizioni di materiale vocale competitivo ha importanti implicazioni cliniche, particolarmente quando si tratta di consigliare i soggetti ipoacusisi. Principalmente il problema è correlato alle performance che ci si possono aspettare in presenza di rumore con o senza audioprotesi e all’importanza di non basarsi solamente sull’udito ma di integrare gli indizi visivi e situazionali per aiutare la comprensione.
Familiarità con il materiale vocale
Numerosi lettori hanno indicato che la familiarità con il materiale vocale è un’importante variabile nella valutazione della discriminazione vocale (Howse, 1957; Hutton e Weaver, 1959; Owens, 1961; Carhart, 1965; Epstein e coll., 1968). Non c’è dubbio che l’utilizzo di parole estranee al vocabolario usuale del paziente possa influenzare in modo marcato la performance stessa. Certamente è una variabile critica di cui rendersi conto ed è responsabilità dell’audiologo selezionare il materiale che sia linguisticamente appropriato per il paziente. La selezione e l’utilizzo di materiali contenenti parole non note al paziente può comportare dei punteggi falsamente bassi e che possono condurre a test non necessari, spese aggiuntive e errori diagnostici o terapeutici.
Risposte a numero chiuso
La performance può essere anche influenzata dal numero di risposte alternative disponibili. L’utilizzo di una metodica di risposta a numero chiuso (ad es. scelta multipla) è un esempio di disponibilità limitata di risposte per ogni prova da cui ci si possano aspettare punteggi più alti rispetto alla metodica aperta (cioè non limitata). Si consideri il caso ipotetico di un test composto di 50 parole stampate o di un compito d’identificazione di una figura con la possibilità di 5 scelte per ogni prova. C’è una possibilità su cinque di una identificazione corretta casuale per ogni singola prova. Nelle applicazioni cliniche reali c’è una maggiore probabilità in alcune prove se il soggetto elimina alcune alternative. I test di questo tipo sono in grado di sovrastimare la capacità di discriminazione vocale. Per questa ragione è importante che il particolare test utilizzato sia annotato sulla scheda del paziente. Un test a risposta chiusa, per esempio MRT, DFDT, MCDT, SSI e CCT impongono restrizioni fisiche e linguistiche dal momento che ognuna richiede un’adeguata acuità visiva e un minimo di abilità nella lettura oltre che un certo grado di risposta motoria. Tali prove sono precluse a quegli individui che non posseggono tali requisiti sensoriali, motori o linguistici.
Certi test ideati per essere usati con bambini anche se non richiedono particolari abilità nella lettura, possono non essere applicabili anche in presenza di un linguaggio adeguato a causa di scarse capacità psicomotorie o di diminuita sensibilità visiva. Quelli che utilizzano un tipo di risposta chiusa possono sovrastimare la discriminazione vocale (per es. con il test WIPI). Il grado di deviazione della norma che ci si può aspettare dall’utilizzo di queste risposte chiuse è funzione del numero di alternative di ogni parola. La raccomandazione precedente riguardante l’annotazione sulla scheda del paziente del particolare test utilizzato, vale anche per i bambini.
Composizione acustica in frequenza
Anche il contenuto frequenziale del segnale vocale è in grado di influenzare la performance di discriminazione vocale. Le prime ricerche di French e Steinberg (1947) utilizzando delle condizioni di filtro passa- alto e passa-basso, avevano dimostrato l’importanza delle frequenze acute per una corretta identificazione di sillabe CVC. La disparità dei risultati ottenuti con sillabe filtrate CVC passa-alto e passa-basso è illustrata in Figura 11. Quando venivano fatte passare tutte le frequenze superiori ai 1000 Hz il 90% delle sillabe veniva riconosciuto correttamente. Comunque, quando venivano presentate solamente le frequenze al di sotto dei 1000 Hz la corretta identificazione del materiale scendeva al 27%. Risultati simili sono stati riportati anche da Hirsh e coli. (1954) utilizzando i monosillabi filtrati CID W-22. Dal punto di vista clinico un deficit uditivo sulle frequenze acute è un’evenienza comune e i punteggi di discriminazione vocale possono essere influenzati dagli effetti combinati della distorsione e del filtraggio. Il ruolo preminente dell’energia contenuta nelle frequenze acute nella comprensione delle parole diviene anche più importante quando si esamina la potenza fonetica dei singoli fonemi. Le consonanti ad alta frequenza che contengono la minore potenza forniscono i maggiori contributi all’intelligibilità (Fletcher, 1953).

Fig. 11 Discriminazione massima per l’articolazione sillabica in condizioni di filtraggio passa basso e passa alto in rapporto alla frequenza di taglio, I punteggi di discriminazione sono stati ottenuti dalle curve di French e Stemberg (1947) ad un guadagno ortotelefonico di 10 dB (75 dB SPL), (Da Goetzinger, C. P. 1978. Word discrimination testing. in J. Katz ed. Handbook of Clinical Audiology, Ed. 2. Williams & Wilkins, Baltimore).
Presentazione a mezza lista rispetto alla lista intera
Nel tentativo di ridurre il tempo di esame e l’affaticamento del paziente è diventata pratica comune per molti audiologi utilizzare liste di discriminazione vocale dimezzate. Tale metodica è stata vagliata da diversi ricercatori utilizzando numerosi soggetti. Le ricerche sull’utilizzo di materiale a mezza lista sono state condotte con il PAL PB-50 (Resnick, 1962; Shutts e colI., 1964; Burke e coll., 1965), con il CID W-22 (Elpern, 1961; Deutsch e Kruger, 1971; Margolis e Millin, 1971; Jirsa e coll., 1975; Penrod, 1980), con il NU-6 (Schumaier e Rintelmann, 1974; Jirsa e coll., 1975; Schwartz e coll., 1977; Beattie e coll., 1978) e con il PBK-50 (Manning e coll., 1975). Allo stato attuale non esiste consenso riguardo l’utilizzo clinico di test a mezza lista. Alcuni autori ne hanno auspicato l’uso, altri lo hanno sconsigliato e altri ne hanno consigliato l’uso ma con certe cautele. Considerevole risparmio di tempo può essere realizzato con metodiche a mezza lista ma non senza rischi. Vi sono due problemi: (1) se i risultati sono validi e (2) se sono affidabili. Se vengono date 25 parole e il punteggio di discriminazione è alto (per es. 92% o più) vi è la ragionevole certezza che non vi siano significativi artefatti in grado di influenzare la performance. Inoltre, dal punto di vista della affidabilità vi sono scarse possibilità che il paziente improvvisamente abbia un calo nella discriminazione nelle ultime 25 parole (una possibilità è che si trovino nelle prime parole un elevato grado di intelligibilità e molti errori nelle ultime 25).
Se vi è un artefatto dovuto ad una deficienza nel sistema di interfono o il materiale è inappropriato per il paziente non è il caso di pensare che altre 25 parole risolveranno il problema. Comunque dai punto di vista dell’affidabilità i punteggi più alti e quelli più bassi sono meno vulnerabili quando si utilizza una lista dimezzata. Thornton e Raffin (1978) hanno sottolineato la correlazione esistente tra errore di misura e lunghezza del materiale. Ciò è illustrato in Figura 12.
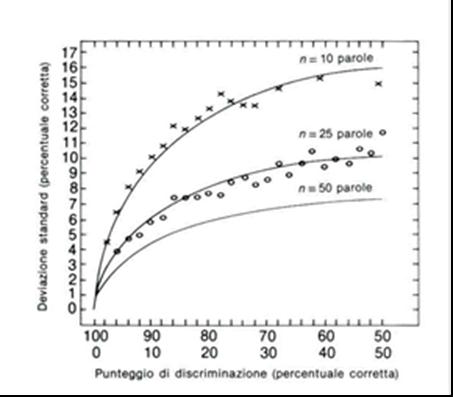
Fig. 12. Deviazioni standard intrasoggettive per test di 10-25 parole raggruppate per punteggi reali stimati (50 parole). Le linee continue mostrano le deviazioni standard di distribuzioni binomiali in funzione di p (in percentuale) per n = 10, n = 25 e n = 50 Le deviazioni standard misurate per n = 10, n = 25 sono evidenziate con X e O rispettivamente (Da Thornton, A. R., e M. J. M. Raffin, 1978. Speech discrimination scores modeled as a binomial variable, J. Speech Hear, Res, 21, 507-518)
Discriminazione massima per l’articolazione sillabica in condizioni di filtraggio passa basso e passa alto in rapporto alla frequenza di taglio, I punteggi di discriminazione sono stati ottenuti dalle curve di French e Stemberg (1947) ad un guadagno ortotelefonico di 10 dB (75 dB SPL), (Da Goetzinger, C. P. 1978. Word discrimination testing. in J. Katz ed. Hanbook of Clinical Audiology, Ed. 2. Williams & Wilkins, Baltimore).
Come si riduce la lunghezza del materiale aumenta la variabilità dei punteggi e più è lontano il punteggio dal 100% o 0% meno fiducia si ha nel valore specifico dell’esame. Thornton e Raffin (1978) hanno fornito gli intervalli di fiducia ed il range di punteggio basati sulla valutazione di più di 4000 pazienti con il CID W-22. Per esempio, un paziente che ha un punteggio del 92% può variare tra il 78% e il 98% con una lista di 50 parole e risulterà ancora dentro la variazione attesa (intervallo fiducia del 95%), mentre il range di variazione atteso 5con una lista di 25 parole è anche maggiore, 72-100%. Per un paziente con un punteggio di discriminazione del 60% il range di variazione per materiale di 50 parole varia dal 42 al 70% e per quello da 25 parole dal 36 all’84%. Si può capire quindi che non si può specificare alcun singolo criterio per valutare la ripetibilità dei risultati del test-retest.
Pro e contro dell’utilizzo della frase portante
Un’altra variabile che può influenzare la discriminazione vocale è l’utilizzo o meno di una frase portante. Si ricordi che Fletcher e Steinberg (1930) avevano trovato che l’identificazione di sillabe CVC era maggiore quando si utilizzava una frase introduttiva. Tipicamente durante i test di discriminazione vocale la frase introduttiva precede la parola utilizzata come stimolo. Le più comuni frasi utilizzate sono «Dica la parola …», «Scriva la parola …» e «Mi mostri …». L’utilizzo di una frase introduttiva nella pratica clinica può essere in declino (Martin e Forbis, 1978). Martin e coil. (1962) non hanno riscontrato differenze nella performance quando viene omessa la frase introduttiva. Altri autori invece hanno riportato il risultato opposto (Gladstone e Sieganthaler, 1971; Gelfand, 1975; Penrod, 1978). Dati pubblicati di recente da parte di Lynn e Brotman (1981) indicano che la frase introduttiva «Dica…» contiene degli aspetti percettivi che possono aiutare il paziente nell’identificare alcuni suoni iniziali della parola test. McLennan e Knox (1975) hanno anche studiato gli effetti dell’omissione della frase introduttiva. Essi hanno comparato la performance di soggetti normoacusici con soggetti con ipoacusia neurosensoriale utilizzando una presentazione convenzionale (frase introduttiva e frequenza controllata dall’esaminatore) e una procedura free-operant (FO) in cui il soggetto ha il controllo della presentazione dello stimolo e perciò è libero di rispondere alla propria velocità. Con questo metodo gli autori hanno indicato che la standardizzazione della presentazione può essere mantenuta utilizzando una lista intera di 50 parole ma si può realizzare anche un risparmio di tempo con la metodica FO. Il punteggio ottenuto dai soggetti normoacusici, e dai soggetti con ipoacusia neurosensoriale non era influenzato dalla omissione della frase introduttiva utilizzando la procedura FO. Inoltre vi è una marcata preferenza per la procedura FO da parte dei soggetti.
Lynn (1962) ha riferito di una modificazione della procedura di discriminazione ideata per risparmiare tempo ma che utilizzava ancora una lista completa di 50 parole. La frase introduttiva è stata mantenuta ma le parole venivano presentate due alla volta in questo test denominato “paired PB-50 discrimination
APPLICAZIONI CLINICHE
Da un punto di vista storico i test di discriminazione vocale hanno avuto in molte applicazione cliniche. Sono stati utilizzati (I) per essere di ausilio nella determinazione della sede della lesione periferica, (2) per valutare l’efficacia e la adeguatezza sociale della comunicazione, (3) per determinare l’indicazione alla chirurgia, (4) per pianificare e valutare i problemi di riabilitazione uditiva, (5) per determinare l’indicazione alla audioprotesi e per selezionare l’amplificazione appropriata e (6) per studiare la funzione uditiva centrale. Vi sono delle marcate differenze nel successo ottenuto in ognuno di questi campi. Prima di discutere le applicazioni cliniche dei test di discriminazione vocale dovrebbe essere sottolineato che le decisioni prese in ognuna delle aree sopra menzionate non sono state prese solamente sulla base delle performance dei test di discriminazione vocale. Piuttosto i test di discriminazione vocale costituiscono uno dei molti fattori che vengono presi in considerazione nel processo decisionale. Alcuni casi illustrativi dell’utilizzo dei test di discriminazione vocale possono essere visti nella Fig. 13
Topodiagnosi di lesione
Il valore diagnostico dei test di discriminazione vocale presi da soli nella determinazione della sede di una lesione è limitato, particolarmente se la discriminazione viene valutata soltanto ad un livello di intensità. I fattori principali che ne limitano l’utilità sono l’ampio range di variazione nei punteggi che si riscontrano per una particolare eziologia e la marcata sovrapposizione di punteggi associati a patologie diverse. I fattori che contribuiscono alla sovrapposizione dei punteggi comprendono l’entità della perdita uditiva, la sua configurazione audiometrica (Bess e Townsend, 1977), la diffusione sugli acuti del mascheramento (Jerger, Tiliman e Peterson, 1960; Martin e Pickett, 1970; Danaher e Pickett, 1975) e la reale abilità di discriminazione vocale del soggetto (Beattie e coli., 1978; Thomton e Raffin, 1978; Penrod, 1979). La variabilità dei punteggi associati a una singola patologia, è chiaramente evidente in uno studio di Johnson (1968) su pazienti con neurinoma dell’acustico confermato chirurgicamente. I punteggi di discriminazione vocale variavano dallo O al 100%. Il valore di test di discriminazione nel differenziare l’ipoacusia cocleare da quella retrococleare viene lievemente aumentato se il punteggio di 30% o meno viene accettato come indicatore di lesione retrococleare.

Fig 13. (A) audiogramma preoperatorio di una ragazza di 19 anni con un colesteatoma che chirurgicamente, si estendeva alla mastoide e alla tuba di Eustachio. La discriminazione vocale era del 96%. (B) Dopo l’intervento (mastoidectomia radicale) non ci fu nessun miglioramento della soglia uditiva e la discriminazione vocale rimase invariata. Fu in seguito adattata una protesi acustica con risultati eccellenti, (C) Una ragazza di 16 anni con una ipoacusia mista congenita. La mancanza di una misura della discriminazione vocale controindicava l’intervento chirurgico per diminuire il gap tra la via ossea-aerea come pure la protesizzazione di quell’orecchio. Fu raccomandata una protesi acustica tipo cros (controlateral routing of signals) (D) Questo caso illustra il sostanziale miglioramento della comprensione del linguaggio con stimolazione bilaterale, avendo il massimo beneficio da una protesizzazione binaurale.
Benchè il riscontro di performance di discriminazione estremamente ridotte siano un forte indicatore di un interessamento retrococleare, non è una conferma definita. Nemmeno i punteggi che cadono ben al di sopra di questo livello escludono una lesione retrococleare.
L’utilità clinica del test di discriminazione vocale nel differenziare le lesioni cocleari da quelle retrococleari viene aumentata dall’utilizzo di una completa funzione performance-intensità utilizzando parole foneticamente bilanciate (Jerger e Jerger, 1971; Dirks e ColI., 1977; Bess e coli., 1979). Con questa metodica il test di discriminazione vocale è completato a livelli di presentazione sempre più alti. Negli individui normoacusici e in quelli con ipoacusia trasmissiva, cocleare o mista, la discriminazione vocale raggiungerà un massimo e ulteriori aumenti del livello di presentazione non mostreranno alcuna variazione (plateau) o solo una modesta riduzione nella comprensione vocale. Nei soggetti con patologia retrococleare si nota un progressivo declino nella discriminazione vocale con l’aumentare dei livello di presentazione oltre il punteggio massimo e ciò comporta il «rollover» della funzione PI-PB come evidenziato in Figura 10. Il rapporto del rollover si calcola sottraendo il punteggio più basso di discriminazione (PB-Min) dal punteggio più alto (PB-Max) dividendo tale risultato per il PB-Max. Un rapporto di 0.45 o più viene considerato indicativo di disfunzione retrococleare (Jerger e Jerger, 1971; Dirks e coll., 1977). Per esempio, il paziente MK con SRT a 10 dB raggiungeva un PB-Max a 40 dB SL del 96% e un PB-Min a 90 dB SL del 52%.
Rapporto rollover = (96 – 52)/96 = 0.46
Un test simile può essere completato utilizzando delle frasi e comparando le funzioni di performance-intensità per le parole e quello per le frasi. Jerger e Hayes (1977) ritengono che questa metodica sia un mezzo per aumentare la sensibilità diagnostica della funzione PI.
Efficacia della comunicazione verbale e adeguatezza sociale
I test di discriminazione vocale forniscono dei dati riguardanti l’adeguatezza sociale dell’udito di un individuo. Comunque quando considerati da soli non sono dei perfetti indicatori della capacità di comunicazione uditiva. Nella maggior parte dei casi i cImici possono ottenere delle informazioni valide riguardo all’efficacia della comunicazione di quegli individui che si trovano agli estremi dei valori misurati ma ciò non può essere fatto certamente in tutti i casi dal momento che esistono delle eccezioni. Inoltre non c’è modo di equi- parare un dato punteggio con un dato livello di funzione sociale, Una serie di altri fattori contribuiscono alla performance relazionale come l’intelligenza, la motivazione, l’esperienza, l’abilità nel completare la frase, fattori situazionali, le aspettative, la ridondanza e il grado di sofisticazione linguistica, per menzionarne alcuni. Ciò non è un motivo valido perché uno non debba condurre i test di discriminazione vocale anzi il contrario. Informazioni di un certo valore si ottengono circa l’entità delle difficoltà e il tipo di errori commessi in condizioni d’ascolto relativamente ben controllate per ogni orecchio. Quando questi dati vengono integrati con l’anamnesi, l’osservazione di come il soggetto comunica durante la seduta e la conoscenza che l’audiologo ha dei fattori che influenzano la comprensione, si può ottenere un quadro abbastanza accurato. Benché non sia possibile una quantificazione precisa, dei giudizi qualitativi si possono esprimere sull’efficacia e l’adeguatezza sociale della comunicazione del soggetto. Spesso l’audiologo inesperto si basa soprattutto su test formali e ignora spesso le informazioni che si possono facilmente ottenere attraverso il colloquio con il paziente. Fidarsi totalmente dei punteggi dei test è un approccio che dovrebbe essere scoraggiato. Al contrario l’audiologo dovrebbe basarsi su tutte le sorgenti disponibili dell’informazione e integrare queste conoscenze per arrivare ad una decisione finale. In ultima analisi è responsabilità dell’audiologo consigliare il paziente riguardo i suoi bisogni comunicativi e questo può essere fatto con una certa fiducia solo quando sono state ottenute informazioni sufficienti.
Ruolo nella scelta chirurgica
La determinazione dell’esistenza di una patologia trasmissiva è facile dato lo stato dell’arte dell’audiometria per via aerea e per via ossea e le misure di impedenzometria. Comunque non si ottiene un guadagno dalla correzione chirurgica di un gap aerea-ossea per migliorare la capacità di comunicazione del soggetto se non è presente una utilizzabile comprensione vocale. D’altro canto ci sono delle volte in cui la chirurgia viene attuata in assenza di una misurabile discriminazione vocale date le condizioni potenzialmente rischiose per la vita. In entrambi i casi è necessario che la documentazione della discriminazione vocale sia ottenuta prima dell’intervento chirurgico.
Dal momento che vi è una probabilità relativamente alta di lateralizzazione quando si utilizzano dei test sopraliminari in una ipoacusia trasmissiva o una ipoacusia monolaterale neurosensoriale, l’esaminatore deve essere certo che il punteggio ottenuto è realmente quello dell’orecchio in esame. Si deve utilizzare il mascheramento in test di discriminazione vocale per eliminare la partecipazione dell’orecchio non in esame. Al contrario dei test tonali per via aerea comunque dove uno deve cercare una differenza di 40 dB o più tra la via area dell’orecchio testato e la via ossea dell’orecchio non in esame, il mascheramento deve essere preso in considerazione anche se vi sono delle differenza molto inferiori a causa della presentazione sopraliminare dello stimolo utilizzato. Se il mascheramento è richiesto ma non può essere utilizzato si dovrebbe annotarlo sull’audiogramma. Riguardo l’utilizzo del mascheramento durante il test di discriminazione vocale in un lavoro di Martin e Forbis (1978) solo il 17% degli audiologi risposero che mascherano quando c’è una differenza di 40 dB tra la SRT e il livello del test di discriminazione vocale e la migliore soglia per via ossea dell’orecchio non in esame. Inoltre il 10% rispose che il mascheramento non viene mai utilizzato durante i test di discriminazione vocale. Le basi razionali di quest’ultimo atteggiamento non sono state chiarite. La differenza di 40 dB sopra citata sembra essere troppo conservativa dal momento che ci si deve aspettare solo la detezione e non la comprensione di uno stimolo vocale. La regola generale è di utilizzare il mascheramento durante il test di discriminazione vocale ogni volta che esiste una differenza di 50 dB o più fra il livello di presentazione all’orecchio in esame e la miglior soglia per via ossea dell’altro o la media della soglia tonale per via ossea dell’orecchio non testato.
Pianificazione e valutazione della riabilitazione
I test di discriminazione vocale forniscono all’audiologo informazioni specifiche riguardo gli errori commessi e un’idea generale delle difficoltà comunicative del paziente. Quando si è soliti pianificare i programmi di riabilitazione uditiva, solitamente vengono condotti ulteriori test comprendenti la valutazione della performance comunicazionale con stimoli uditivi, visivi e con stimoli combinati visuo-uditivi. La selezione della strategia riabilitativa più appropriata è migliorata determinando quanto il paziente usa la vista (Erber, 1971, 1972). I risultati formano la base non solo per la consulenza riguardante gli effetti dell’ipoacusia, ma anche forniscono dati specifici utilizzati nella formulazione delle strategie di riabilitazione. I test di discriminazione vocale con o senza vista (cioè la lettura labiale) sono di aiuto negli sforzi di riabilitazione uditiva come metodica di valutazione dei progressi raggiunti. Giolas (1982) ha fatto alcune considerazioni specifiche su come il test di discriminazione vocale possa essere utilizzato per fornire una indicazione del grado di miglioramento uditivo che un paziente possa ottenere durante un processo di riabilitazione.
MODIFICHE
Esame in soggetti adulti
Variazioni nella normale procedura sono spesso necessarie quando si esaminano alcuni soggetti adulti. Tale necessità probabilmente è più stringente in pazienti che possiedono una limitata capacità di linguaggio. Con questi individui è spesso più appropriato utilizzare dei test ideati per i bambini data la ridotta richiesta linguistica. Con pazienti con una capacità di discriminazione vocale marcatamente ridotta, la lista di parole monosillabiche può essere abbandonata a favore delle frasi. Anche se non facilmente quantificabili esse possono essere più significative rispetto al punteggio in percentuale ottenuto utilizzando una lista di parole monosillabiche poiché informano circa l’uso che il paziente fa dei residui uditivi quando dispone di ulteriori spunti dalla semantica, dalla sintassi e dalla prosodia. Inoltre in pazienti con performance vocale estremamente scadente ciò potrebbe essere una procedura meno frustrante. Miller e coll. (1951) hanno dimostrato che anche con una discriminazione vocale molto bassa ci può essere una discreta abilità a seguire una conversazione.
Si devono anche prendere in considerazione delle modifiche nelle modalità di risposta con i pazienti che non possiedono un linguaggio normale o che hanno un linguaggio non intellegibile: con alcuni individui ritardati, con disordini gravi dell’articolazione, con i laringectomizzati e i balbuzienti. Bisogna inoltre considerare la possibilità di variare sia il materiale che i paradigmi di risposta quando si esaminano soggetti afasici e handicappati multipli. Altre complicazioni come la cecità, l’analfabetismo, disordini emotivi e motori impongono limitazioni simili sui test di discriminazione vocale e il clinico deve essere attento alle necessità di modifica del materiale e delle metodiche d’esame.
Patologia uditiva centrale
I test di discriminazione vocale sono idealmente adatti a valutare i disordini uditivi centrali troncoencefalici e corticali dal momento che essi richiedono uno stimolo complesso. Sono spesso utilizzati con metodica dicotica presentati con rumore competitivo, messaggi competitivi o degradati dal punto di vista acustico (nel tempo, nella frequenza, nelle interruzioni periodiche). I test vocali nella valutazione dei processi uditivi centrali sono presentati a parte.
Esame con bambini
11 test di discriminazione vocale con i bambini può essere un compito difficile. Di importanza critica è la selezione del materiale che deve far parte dei vocaboli che il bambino comprende. Attenta valutazione deve essere anche data alle modalità di selezione delle modalità di risposta e delle strategie di rinforzo, date le difficoltà che possono insorgere nell’attribuire il punteggio per errori di articolazione e per il frequente incontro di oggetti taciturni per natura e non cooperanti.
Con i bambini che non possono o non vogliono rispondere verbalmente, l’approccio psicomotorio può essere impiegato utilizzando figure o oggetti comuni selezionati per il loro alto interesse e perché molto adatti al test di discriminazione vocale. Il bambino può essere frequentemente coinvolto nella conversazione oppure partecipa volentieri a giochi «Simone dice…» utilizzando comandi semplici.
Un problema frequente che si incontra con i bambini è il loro rifiuto ad accettare le cuffie. Il Capitolo 32 considera questo problema. Una alternativa è utilizzare un ricevitore per via ossea per inviare i segnali vocali. Questo si è dimostrato un approccio utilizzabile con i bambini e gli adulti (Edgerton e coll., 1977; Valente e Stark, 1977; .Johnson e Bordenick, 1978, Karlsen e Goetzinger, 1980). Nonostante l’apparente incongruenza i bambini spesso accettano il posizionamento di un oscillatore osseo anche se rifiutano categoricamente le cuffie. Naturalmente la metodica soffre dello svantaggio dell’impossibilità di mascherare l’orecchio non testato.
RIASSUNTO
Questo capitolo ha riesaminato lo sviluppo dei test di discriminazione vocale negli Stati Uniti e ha descritto alcuni dei più comuni materiali vocali per i test attualmente disponibili. Sono stati discussi i fattori che influenzano la performance e sono state anche presentate brevemente le principali applicazioni cliniche. Sono state inoltre discusse alcune modifiche procedurali che frequentemente si ritrovano nella pratica clinica.
AUDIOMETRIA VOCALE
REFERTAZIONE E INTERPRETAZIONE DEI TRACCIATI.
• MODALITÀ DÌ SOMMINISTRAZIONE
Per poter procedere all’esecuzione di una audiometria vocale, l’esaminatore deve preparare il paziente alla prova stessa dicendo che sentirà una voce e non altri suoni. Gli si spiega quale tipo di materiale verbale verrà usato (es. frasi, parole, logotomi) in modo che il paziente sappia cosa si deve aspettare. L’anticipazione di questi particolari predispone bene il paziente, rendendo il riconoscimento del messaggio più immediato e risparmiando tempo. Inoltre, l’esaminatore deve dire al paziente di aspettare la fine del messaggio verbale prima di ripetere ciò che ha sentito (chiaramente nella registrazione c’è sempre una pausa apposita). E’ importante far capire al paziente che deve ripetere il messaggio così come lo sente. Il materiale vocale impiegato, inciso su CD preregistrati per assicurare l’affidabilità tra un test e l’altro e per sottoporre ciascun paziente allo stesso tipo di test, viene inviato con diverse vie di stimolazione (in cuffia, per via ossea, in campo libero). Il lettore CD viene collegato ad un audiometro con ingresso ausiliario ed in seguito viene tarato il sistema per mezzo del tono di presentazione (V. U. meter ) che si trova nella prima traccia del disco (1000Hz – 19dB SPL). L’intensità della presentazione iniziale viene stabilita ad un livello corrispondente alla media tonale per le frequenze della voce (500 – 1000 – 2000 Hz ) più 20-30 dB.
Per quanto riguarda le prove vocali normali, nelle ipoacusie bilaterali simmetriche, il materiale può essere presentato in condizioni di ascolto dicotico, cioè tramite cuffia simultaneamente ad entrambi gli orecchi. Invece se siamo in presenza di una ipoacusia bilaterale asimmetrica, si devono esaminare i due orecchi separatamente in modo monoaurale. In questo caso si ricorre al mascheramento necessario quando la differenza tra la perdita media tonale nei due orecchi per le frequenze della voce è superiore ai 40Db HL. Quando vengono usati test a viva voce, una variazione nel rumore del test di segnale, nell’accento, nel momento in cui il test è eseguito e altri fattori possono contaminare i risultati del test a un livello non noto. Nondimeno, i test viva voce, talvolta, sono necessari, p. es., per i pazienti con morbo di Alzheimer e per quelli che hanno difficoltà a completare un compito
La somministrazione può avvenire in cuffia, per via ossea ed in campo libero. Tutte e tre le modalità prevedono l’uso dell’audiometro, mentre il test in campo libero può essere effettuato anche senza alcun supporto tecnologico, con la viva voce dell’esaminatore seduto di fronte al paziente ad un metro di distanza. In viva voce, poi, il test viene eseguito con e senza l’ausilio della lettura labiale, in presenza o meno di rumore di competizione.
• INTENSITÀ E VELOCITÀ DÌ ELOQUIO
Il materiale pre-registrato può essere proposto:
• In cuffia o per via ossea, ad intensità decrescenti, mantenendo costante la velocità di eloquio;
• In campo libero, mantenendo costante intensità e velocità di eloquio della voce di conversazione (60 dB SPL), ma associandola ad una competizione che viene fatta variare d’intensità con rapporti Segnale/Rumore (S/R) variabili e cioè +20dB , +10dB ,0 dB; -10 dB;-20 dB;-30 dB.
Le prove in viva voce sono effettuate con la voce di conversazione, ma con una velocità di eloquio la più rapida possibile. Il test così effettuato viene denominato Speech Tracking.
4. MASCHERAMENTO
Nell’audiometria vocale il mascheramento si rende necessario quando la diferenza tra la perdita media tonale nei due orecchi per le frequenze della voce è superiore ai 40 dB HL. Vari tipi di mascheramento possono essere adoperati come :
– Rumore Rosa ( Pink Noise – PN ): l’energia è uguale per ogni ottava per tutte le frequenze (125 – 8000 Hz );
– Speech Noise (SPN): l’energia è uguale per tutte le frequenze specifiche della voce(500-1000-2000 Hz). Questo tipo di rumore è più efficace ma non è a disposizione su tutti gli audiometri;
– Rumore tipo “cocktail party” che simula le condizioni acustiche del rumore di fondo (voci, bicchieri ecc.. ) durante un cocktail;
– Rumore tipo “babble”: le voci di diversi interlocutori vengono miscelate producendo un fattore di interferenza maggiore rispetto al rumore randomizzato senza voci. Questa maggiore interferenza è dovuta al fatto che il babble contiene falsi indizi uditivi (ad es. occasionali parole vengono riconosciute nei momenti di pausa) e questo aumenta la difficoltà per i processi di attenzione e di memoria che sono coinvolti al riconoscimento del messaggio verbale primario.
In audiometria vocale si deve ricorrere al mascheramento ogni volta che si ritiene che l’orecchio controlaterale possa intervenire nella determinazione della funzione di intelligibilità dell’orecchio in esame.
Vediamo quindi, analogamente al mascheramento in audiometria tonale, quando e come mascherare.
Partendo dal presupposto che per la lingua italiana le frequenze più importanti ai fini intellettivi sono quelle comprese fra 1000 e 2000 Hz, si può stabilire che occorra mascherare quando la differenza fra soglia tonale aerea per tali frequenze e soglia tonale ossea controlaterale per le stesse frequenze sia pari o superiore a 40 dB.
Studebaker (1964) consiglia di considerare pure la frequenza 500 Hz. mentre altri autori ritengono il valore di 40 dB già eccessivo (Martin 1966). Circa il come mascherare, qui le regole non sono altrettanto precise come in audiometria tonale ove il livello di mascheramento viene calcolato sulla soglia dell’orecchio migliore.
L’audiometria vocale non è quasi mai condotta a livello di soglia quindi il mascheramento va regolato in base al volume del messaggio inviato è sarà all’incirca uguale all’intensità dello stesso meno i 40 dB dell’attenuazione interaurale.
Poiché con tale regola non si può sempre e con sicurezza escludere una parziale componente da mascheramento centrale, anche se è sempre raccomandato l’uso di un inserto, è stato proposto di correggere tale eventualità riducendo la soglia così ottenuta di 5 dB
Circa il materiale usato per mascherare, questo deve coprire tutto l’ambito spettrale vocale, la scelta cade quindi fra rumore bianco (WN vedi sopra) o rumore di concione (SN vedi sopra) e rumore rosa (PN vedi sopra).
Per le caratteristiche intrinseche del rumore mascherante, la curva determinata con mascheramento tramite PN ha andamento simile a quella determinata in assenza di mascheramento e risulta spostata a destra in maniera proporzionale all’intensità di mascheramento, mentre quell a rilevata mediante mascheramento con WN o, anche se in grado minore, con SN risulta sempre più inclinata e non direttamente proporzionale al livello di mascheramento
5. RIDONDANZA
Un aiuto al riconoscimento del messaggio verbale ci viene dato dalla Ridondanza la quale viene definita come la quantità di informazioni in eccesso rispetto a quelle richieste per il riconoscimento del messaggio verbale.
Esistono due tipi di ridondanza: la ridondanza estrinseca e la ridondanza intrinseca.
-LA RIDONDANZA ESTRINSECA è legata esclusivamente al contenuto del messaggio verbale e si può dividere in tre livelli:
– FONETICA legata al contenuto fonetico del messaggio(logotomi),
– SINTATTICA legata alla struttura grammaticale del messaggio(frasi normali e frasi sintetiche),.
– SEMANTICA legata al significato del messaggio(parole bisillabiche e frasi normali).
I tre tipi di ridondanza si combinano variamente fra loro, avremo così:
logotomi: ridondanza fonemica
parole bisillabiche: ridondanza semantica (-) e fonemica (+)
frasi sintetiche: ridondanza fonemica (-) semantica (-) e sintattica (+)
frasi normali: ridondanza fonemica (-) semantica (+) e sintattica (+)
La componente fonemica delle frasi normali può poi essere ridotta impiegando frasi distorte o frasi accelerate.
Per chiarire con un esempio: i logotomi ( reva, mebo, lome ecc.) hanno solamente una ridondanza fonetica ed il riconoscimento avviene in base alle informazioni acustiche percepite.
Le parole bisillabiche (fiele, orlo, cento) contengono sia la ridondanza fonetica che semantica per cui il significato viene aggiunto alle informazioni acustiche ed il riconoscimento della parola diventa più facile.
Le frasi normali (Gli esploratori partono per il polo) contiene tutte e tre tipi di ridondanza, in quanto la struttura grammaticale integra le informazioni presenti nel messaggio.
Unitamente alla ridondanza estrinseca correlata al contenuto del messaggio, abbiamo una ridondanza intrinseca del sistema nervoso centrale che mediante meccanismi vari integra il messaggio ricevuto e subentra per la correzione di eventuali errori nell’ identificazione del messaggio verbale. Essa si riduce per la presenza di una patologia che coinvolge la via acustica centrale e può essere svelata utilizzando del materiale a bassa ridondanza estrinseca.
Dallo schema seguente si evince con maggiore chiarezza l’importanza della ridondanza estrinseca e intrinseca sulla intelligibilità vocale.
|
Ridondanza del messaggio(estrinseca)
|
Ridondanza neurale(intrinseca )
|
Intelligibilità
|
| Normale | Normale |
Ottima
|
| Normale | Ridotta |
Sufficiente
|
| Ridotta | Normale |
Sufficiente
|
Punteggio
Il punteggio può essere segnato o in base a parole/frasi intere o in base a singoli fonemi. Il numero degli elementi correttamente identificati viene convertito in un valore percentuale e registrato come punteggio relativo al livello specifico di stimolazione.
Le risposte vengono fornite dal paziente che ripete il messaggio a viva voce, oppure mediante l’utilizzo di cartelle scritte (closed-set response), dove il paziente deve segnalare la risposta corretta su un apposito modulo a scelta multipla (oppure indicando l’immagine giusta come è il caso nei bambini).
6. SOGLIE
L’audiometria vocale utilizza come stimolo verbale generalmente le parole bisillabiche a senso compiuto.
I logotomi vengono utilizzati per evidenziare eventuali deficit di discriminazione fonetica . Le frasi vengono usate da qualche autore in campo pediatrico( > 6 anni) o nelle prove speciali con messaggio controlaterale.
Facendo riferimento ad una lista di parole (10-20 ), si contano le risposte esatte per le varie intensità che variano di 10 dB per volta.
I risultati che si ottengono vengono registrati su un diagramma modificato da Davids sulla cui ascissa viene indicato l’intensità in dB e sull’asse delle ordinate la percentuale di risposte esatte.
In audiometria si distinguono tre soglie:
– Soglia di detezione che corrisponde alla soglia in cui il paziente sente parlare , ma non è in grado di ripetere quello che sente. Nei soggetti normoudenti tale soglia è a 0 dB;
– Soglia di percezione che corrisponde al livello in dB al quale il paziente ripete in modo esatto il 50% del messaggio verbale. Nei soggetti normali tale soglia è situata a 10 dB per le frasi, 15 dB per le parole, 20 dB per i logotomi.
– Soglia di intellezione corrisponde al livello in dB in cui il paziente raggiunge il 100% di intelligibilità per il materiale verbale presentato. Nei soggetti normali tale soglia viene raggiunta a 20 dB per le frasi, 25 dB per le parole, 30 dB per i logotomi.
RISPOSTA RICHIESTA AL PAZIENTE
Istruzioni al paziente
L’esaminatore deve preparare il paziente alla prova vocale dicendo che sentirà una voce e non altri suoni (toni puri). Gli deve spiegare il tipo di materiale verbale che verrà usato (es. frasi, parole, logotomi) in modo che il paziente sappia che cosa si deve aspettare. L’anticipazione di questi particolari predispone bene il paziente, rendendo il riconoscimento del messaggio più immediato e risparmiando tempo.
Inoltre, l’esaminatore deve dire al paziente di aspettare la fine del messaggio verbale prima di ripetere ciò che ha sentito (nella registrazione c’è sempre una apposita pausa). E importante far capire al paziente che deve ripetere il messaggio “così come Io sente”, perché nell’audiometria vocale anche gli sbagli assumono una certa importanza.
Livello di presentazione L’intensità della presentazione iniziale viene stabilita ad un livello corrispondente alla media tonale per le frequenze delle voce (500-1000-2000 Hz) più 20-30 dB. Per quanto riguarda le prove vocali normali, nelle ipoacusie bilaterali simmetriche il materiale può essere presentato in condizioni di ascolto dicotico, ossia tramite cuffia simultaneamente ad entrambi gli orecchi. In presenza di una ipoacusia bilaterale asimmetrica, invece, si devono esaminare i due orecchi separatamente (in condizioni monoaurali), usando il mascheramento per l’orecchio peggiore se necessario; in tal caso, come per l’audiometria tonale, si inizia con l’orecchio migliore.
Il livello stabilito per la presentazione iniziale spesso corrisponde al livello di comodo ascolto (MCL – most comfortable loudness level) del paziente. Segue la presentazione di altre liste a livelli corrispondenti a MCL + 10, + 20, -10 e -20 o oltre se necessario, passando da un minimo di 5 ad un massimo di 7 presentazioni dalle quali si ricava la curva di articolazione.
Curve di articolazione I risultati vengono registrati su un apposito grafico dove la percentuale di frasi/parole correttamente identificate viene segnata in funzione dell’intensità dello stimolo. Nei normoudenti, il profilo della curva di articolazione varia in rapporto al grado di ridondanza del materiale (Fig. 14).
Il paziente può identificare lo stimolo verbale all’interno di una lista chiusa (test di identificazione), oppure ripetere ciò che ha sentito (test di riconoscimento). La velocità di ripetizione è libera con il materiale preregistrato oppure, la più veloce possibile nel test Speech Tracking.
È importante ricordare che nello Speech Tracking il paziente non deve capire il significato delle parole, ma solo ripeterle. Si tratta quindi di un test di riconoscimento.
Con i materiali preregistrati, si inviano blocchi di dieci items recitati uno per volta del materiale scelto:
• ad intensità decrescenti con intervalli di 10 dB,
• oppure ai vari rapporti S/R, quando l’intensità del messaggio primario è mantenuta fissa e le risposte corrette ripetute o identificate dal paziente vengono calcolate percentualmente nel range che va dal 100 % allo 0%.
Nello Speech Tracking si contano invece il numero di parole correttamente ripetute in un minuto (P.A.M. parole al minuto) nelle quattro modalità di somministrazione e cioè:
• Lettura labiale in quiete (LLQ)
• Lettura labiale nel rumore (LLR)
• Bocca schermata in quiete (BSQ)
• Bocca schermata nel rumore (BSR).
REPORT DEI RISULTATI
I risultati possono essere riportati su grafici, oppure numericamente.
In audiometria vocale diagnostica con materiale preregistrato trasmesso in cuffia o per via ossea a intensità decrescenti, si costruisce la curva di articolazione vocale all’interno di un grafico che vede sull’asse delle ascisse i decibel e sull’asse delle ordinate la percentuale di risposta.
In base alla topodiagnosi si ottengono dei profili caratteristici per le ipoacusia trasmissive, quelle cocleari e quelle retro cocleari.

Fig. n°14
Curve audiometriche vocali nei diversi tipi di ipoacusia. A) curva normale nella normoacusia, B) curva spostata verso destra e raddrizzata rispetto alla normale nell’ipoacusia mista, C) curva spostata verso destra e parallela alla curva normale, D) curva spostata verso destra e molto obliqua rispetto alla curva normale; E) curva “a plateau” nell’ipoacusia percettiva cocleare ;F) curva a campana nell’ipoacusia percettiva retro cocleare (con roll-over)
7. CURVE
Il tracciato audiometrico vocale è rappresentato da una curva di articolazione o di intelligibilità. Tale curva, ottenuta unendo i valori per ogni intensità, ha la forma di S italica. Sulle basi di quanto detto la valutazione della
discriminazione vocale viene effettuata in base a due criteri:
– Quantitativo, il livello della soglia di percezione vocale (50% ) del paziente viene paragonato a quello ottenuto per lo stesso materiale fonetico nei normoudenti. La differenza viene espressa in dB ;
– Qualitativo i diversi gradienti della curva di articolazione sono indicativi della patologia.Quindi, nelle ipoacusie di trasmissione la curva di articolazione vocale per le parole è spostata verso destra.In generale, possiamo riscontrare due tipi di curve :
– Più raddrizzata rispetto alla normale e spostata verso destra. Si riscontra nelle ipoacusie trasmissive caratterizzate da una perdita maggiore per le frequenze gravi rispetto alle acute (ad esempio nell’otosclerosi).
– Parallela alla curva normale e spostata verso destra, si riscontra nelle ipoacusie trasmissive pantonali.
– Nelle ipoacusie di tipo neurosensoriali è difficile che il paziente riesca a raggiungere il 100% di intelligibilità. Questa scarsa risoluzione per la voce può essere attribuita sia alla perdita relativamente maggiore per i componenti di media/alta frequenza (suoni consonantici) sia per i fattori di distorsione di loudness tipici di queste perdite.
Le curve possono essere :
– oblique,
– a plateau,
– a cupola,
– a campana con roll-over.
-Le curve oblique si riscontrano nelle sordità nelle quali esiste uno squilibrio di frequenze con deficit uditivo maggiore per le frequenze acute rispetto alle gravi.
-Le curve a plateau sono caratterizzate dal fatto che aumentando l’intensità non migliora l’intellegibilità. Sono tipiche delle lesioni cocleari per la presenza del fenomeno del recruitment che determina una distorsione del messaggio
in rapporto alla intensità dello stesso.
-Le curve a cupola sono simile alle precedenti ma alle alte intensità ridiscende lievemente verso il basso. Si riscontra nelle forme cocleari con recruitment marcato.
-Le curve a campana, si riscontrano nelle lesioni retrococleari (neurinoma dell’VIII°) ed è generalmente monolaterale. Le forme bilaterali sono associate talora a patologie del tronco. Questa diminuzione di intelligibilità può arrivare allo 0% ed è legata a fenomeni di distorsione in rapporto all’intensità. E’ inoltre caratterizzato da una notevole pendenza da un breve plateau non superiore al 50-60% di identificazione e da una rapida caduta dopo il plateau che la riporta talvolta allo 0%. Si può verificare che una curva vocale con rollover si associ ad un audiogramma tonale solo lievemente compromesso
(sulle alte frequenze). Questo reperto indicativo di lesione neurale e/o del tronco encefalico viene detto Dissociazione Verbo-Tonale.
BIBLIOGRAFIA
Antonelli A.R.; 1977.Barocci R.; Mantovani M.: Un nuovo materiale vocale in lingua italiana: le frasi sintetiche. Nuovo Arch. It. Otol., 5, 1-13,.
Asher, J. W. 1958. Intelligibility tests: a review of their standardization, some experiments, and a new test. Speech Monogr. 25, 14—28.
American National Standards Institute. (2002). Methods for the calculation or the speech intelligibility index (ANSI S.35-1997. R2002). New York: Author.
American National Standards Institute (2004), American National Standards specifications for audiometers (ANSI S3.6-2004). New York: Author
American Speech-Language-Hearing Association. (1988) Guidelines for determining threshold level for speech ASHA. 30. 85—89
American Speech-Language-Hearing Association (1991) Sound field measurement tutorial ASHA. 33. 25—37
Bess. F( 1983) Clinical assessment or speech recognition. In D. Konkle & W. Rintelmann (Eds ), Principles or speech audiometry (pp 127-201)Baltimore MD: Academic Press .
Azzi A.: 1950.Prove di acumetria vocale per la lingua italiana. Arch. 1ml. OtoI. 5, 45-84,.
Bilger, R:C:, Nuetzel.J. M . Rabinowitz, W. M. , & Rzeczkowski, C. (1984)
Beattie, R. C., D. A. Svihovec, and B. J. Edgerton. 1978. Comparison of speech detection and spondee thresholds and half- versus full-list intelligibility scores with MLV and taped presentations of NU-6. J. Am. Aud, Soc 3, 267-272.
Bess, F. H., and T. H. Townsend. 1977. Word discrimination for listeners with flat sensorineural hearing losses. J. Speech Hear. Disord. 42, 232—237.
Bess, F. H., A. F. Josey, and L. E. Humes. 1979. Performance intensity functions in cochlear and eighth nerve disorders. Am. J. Otol. 1, 27—31.
Black, J. W. 1957. Multiple choice intelligibility tests. 3. Speech Hear. Disord. 22, 213—235.
Bocca E; Pellegrini A.: 1950.Studio statistico sulla composizione della fonetica della lingua italiana e sua applicazione pratica all’audiometria con la parola. Arch. hai. Otol. 5, 116-141,.
Bortolini U.; Degan F.; Minnaja C,; Paccagnella L.; Zilli G.: 1978.Statistics for a stochastic model of spoken italian, 580-586.In Dressler W.U.; Meld W. (EDS.): Proceedings of Xllth International Congress of Linguistics, Innsbruck,.
Brandy, W. T. 1966. Reliability of voice tests of speech discrimination. 3. Speech Hear. Res, 9, 461—465.
Bryant, W. S. 1904. A phonographic acoumeter. Arch. Otolaryngol. 33, 438—443.
Burdo S.; Orsi C.: Frasi in lingua italiana con parole bisillabiche. I Care, suppl. al n° 2, 32-34, aprile-giugno1995.
Burke, K. S, R. E. Shutts, and W. P. King. 1965. Range of difficulty of four Harvard phonetically balanced word lists. Laryngoscope 75, 289—296.
Burney, P. A. 1972, A survey on hearing aid evaluation procedures. Asha 14, 439—444.
Calearo C. Audiometria vocale. Atti del XIII Congresso della Soc. It. di Audiol. 1972.
Campbell, G. A. 1910. Telephonic intelligibility. Philo. Mag. J. Sci. 19 (109), 152—159.
Campbell, R. A. 1965, Discrimination and word test difficulty. 3. Speech Hear. Res. 8, 13—22.
Carhart, R. 1946a Monitored live-voice as a test of auditory acuity. 3. Acoust. Soc. Am. 17, 338—349.
Carhart, R. 1946b. Selection of hearing aids. Arch. Otolaryngol. 44, 1—18.
Carhart, R. 1965. Problems in the measurement of speech discrimination. Arch. Otolaryngol. 82, 253— 260.
Cox. E (1981) Using LDL to establish hearing aid limited levels Hearing Instruments 32. 16—20.
Crandall, I. B. 1917. The composition of speech. Phys. Rev. 10, 74—76.
Crystal, T. H., &House, A.S. (1990) Articulation rate and the duration or syllables and stress groups in connected speech Journal of the Acoustical Society of America. 88. 101—112
Cutugno F.; Prosser S.; Turrini M. 2000.Audiometria vocale – vol. I; ed. GN. ReSound Italia,.
Danaher, E. M., and 3. M. Pickett. 1975. Some masking effects produced by low frequency vowel formants in persons with sensorineural hearing loss. J. Speech Hear. Res. 18, 261—271.
Davis, H., and 5. R. Silverman. 1960. Hearing and Deafness. Holt, Rinehart and Winston, New York.
Davis, H., and S. R. Silverman. 1978, Hearing and Deafness, Ed. 4. Holt, Rinehart and Winston, New York.
Davis, H., K. C. Morrical, and C. E. Harrison. 1949. Memorandum on recording characteristics and monitoring of word and sentence tests distributed by Central Institute for the Deaf. J. Acoust. Soc. Am. 21, 552—553.
De Filippo C.L., Lasing C.R., Elfenbein J.L. 1994.Deriving passage difficulties for a tracking Study via the Cloze Technique. J. Am. Acad. Audiol.; 5; 366-378.
De Filippo C.L., Scott B.A 1978.method for training and evaluating the reception of ongoing speech.Journal of the acoustical Society of America; 63; 1186-1192.,
De Mauro T.: 1989.Guida all’uso delle parole. Editori Riuniti, Roma,.
De Mauro T.; Mancini F.; Vedovelli M.; Voghera M.: 1993.Lessico di frequenza dell’italiano parlato. ETAS Libri, Milano,
Deutsch, L. J., and B. Kruger. 1971. The systematic selection of 25 monosyllables which predict the CID W-22 speech discrimination score. J. Aud. Res. 11, 286—Q90.
Dewey, G. 1923. Relative Frequency of English Speech Sounds. Harvard University Press, Cambridge, MA.
Dirks, D. D., C. Kamm, D. Bower, and A. Betsworth. 1977. Use of performance-intensity functions for diagnosis. J. Speech Hear. Disord. 42, 408—415.
Dubno, 3. R., and D. D. Dirks. 1983. Suggestions for optimizing reliability with the Synthetic Sentence Identification Test. J. Speech Hear. Disord. 48, 98— 103.
Edgerton, B. J., J. L. Danhauer, and R. C. Beattie. 1977. Bone conducted speech audiometry in normal subjects. 3. Acoust. Soc. Am. 3, 84—87.
Egan, J. P. 1948. Articulation testing methods. Laryngoscope 58, 955—991.
Eldert, E., and H. Davis. 1951. The articulation function of patients with conductive deafness. Laryngoscope 61, 896—909.
Elliot, L. L.. 1963. Prediction of speech discrimination scores from other test information. J. Aud. Res. 3, 35—45.
Elpern, B. S. 1960. Differences in difficulty among the CID W-22 auditory tests. Laryngoscope 70, 1560— 1565.
Elpern, B. S. 1961. The relative stability of half-list and full-list discrimination tests. Laryngoscope 71,30—36.
Epstein, A., T. C. Giolas, and E. Owens. 1968. Familiarity and intelligibility of monosyllabic word lists. 3. Speech Hear. Res. 11, 435—438.
Erber, N. P. 1971. Auditory and audiovisual reception of words in low frequency noise by children with normal hearing and children with impaired hearing. J. Speech Hear. Res. 14, 496—512.
Erber, N. P. 1972, Auditory, visual, and auditory visual recognition of consonants by children with normal and impaired hearing. J. Speech Hear. Res. 15, 413—422.
Erber, N. P. 1980. Use of the auditory numbers test to evaluate speech perception abilities of hearing impaired children. 3. Speech Hear. Disord. 45, 527— 532.
Esprit Project 1541, 1988.Multi-lingual speech input-output assessment, Methodology and standardisation,
(SAM). Meeting report: labelling transcription and 7nanagement methods for speech databases,.
Etymotic Research (2001) QuickSIN speech-in-noise test St. Louis: Auditec.
Etymotic Research (2005) BKB SIN speech-in-noise test St Louis: Auditec.
Fairbanks, G. 1958. Test of phonemic differentiation:
the rhyme test. 3. Acoust. Soc. Am. 30, 596—599.
Findlay, R. C. 1976. Auditory dysfunction accompanying noise-induced hearing bss. 3. Speech Hear. Disord. 41, 374—380.
Finitzo-Hieber, T., I. J. Gerlin, N. D. Matkin, and E.Cherow-Skalka. 1980. A sound effects recognition test for the pediatric evaluation. Ear Hear. 1, 271— 276.
Fletcher, H. 1922. The nature of speech and its interpretation. 3. Franklin Inst. 193, 729—747.
Fletcher, H. 1929. Speech and Hearing. Van Nostrand, Princeton, NJ.
Fletcher, H. 1950. A method of calculating hearing loss for speech from the audiogram. Acta Otolaryngol. Suppl. 90, 26-37.
Fletcher, H. 1953. Speech and Hearing in Communication. Van Nostrand, Princeton, NJ.
Fletcher, H., and 3. C. Steinberg. 1930. Articulation testing methods. 3. Acoust. Soc. Am. 1, 1—97.
French, N. R., and 3. C. Steinberg. 1947. Factors governing the intelligibility of speech sounds. 3. Acoust. Soc. Am. 19, 90—119.
French, N. R., C. W. Carter, and W. Koenig. 1930. The words and sounds of telephone conversations. Beh Sys. Tech. 3. 9, 290—324.
Garstecki, D. C., and A. Mulac. 1974. Effects of test material and competing message on speech discrimination. 3. Aud. Res. 3, 171—178.
Geffner, D., and N. Donovan. 1974. Intelligibility functions of normal and sensorineural loss subjects on the W-22 lists. 3. Aud. Res. 14, 82—86.
Gelfand, S. A. 1975. Use of the carrier phrase in live voice speech discrimination testing. J. Aud. Res.15, 107—110.
Gengel, R. W., and G. L. Kupperman, 1980. Word discrimination in noise: effect of different speakers. Ear Hear. 1, 156—160.
Gibbon D.; Moore R.; Winski R.: 1997.Handbook of standard and Resources for spoken language systems. Mouton de Gruyter, Berlin,.
Giolas, T. G. 1982. Hearing Handicapped Adults. Prentice-Hall, Englewood Cliffs, NJ.
Gladstone, V. S., and B. M. Sieganthaler. 1971. Carrier phrase and speech intelligibility test score. 3. Aud. Res. 11, 101—103.
Goldman, R., M. Fristoe, and R. Woodcock. 1970. Test of Auditory Discrimination. American Guidance Services, Circle Pines, MN.
Griffiths, 3. D. 1967. Rhyming minimal contrasts: a simplified diagnostic articulation test. 3. Acoust. Soc. Am. 42, 236—241.
Harris, 3. D. 1965. Puretone acuity and the intelligibility of everyday speech. 3. Acoust. Soc. Am. 37, 824—830.
Harris, 3. D., H. L. Haines, and C. K. Meyers. 1956. A new formula for using the audiogram to predict speech hearing loss. Arch. Otolaryngol. 64, 447.
Haskins, H. A. 1949. A phonetically balanced test of speech discrimination for children. Master’s thesis, Northwestern University, Evanston, IL.
Hirsh, I. 3. 1952. The Measurement of Hearing. McGraw-Hill, New York.
Hirsh, 1. 3., H. Davis, 5. R. Silverman, E. G. Reynolds, E. Eldert, and R. W. Benson. 1952. Development of materials for speech audiometry. 3. Speech Hear. Disord. 17, 321—337.
Hirsh, I. 3., E. G. Reynolds, and M. Joseph. 1954.Intelligibility of different speech materials. J. Acoust. Soc. Am, 26, 530—538.
House, A. S., C. E. Williams, M. H. L. Necker, and K. D. Kryter. 1965. Articulation testing methods. Consonantal differentiation in a closed response set. J. Acoust. Soc. Am. 37, 158—166.
Howse, D. 1957. On the relation between the intelligibility and frequency of occurrence of English words. J. Acoust. Soc. Am. 29, 296—305.
Hudgins, C. V., J. E. Hawkins, J. E. Karlin, and S. 5. Stevens. 1947. The development of recorded auditory tests for measuring hearing loss for speech. Laryngoscope 57, 52—89.
Hughson, W., and E. Thompson. 1942. Correlation of hearing acuity for speech with discrete frequency audiograms. Arch. Otolaryngol. 36, 526—540.
Hutton, C., and S. J. Weaver. 1959. PB intelligibility and familiarity. Laryngoscope 67, 1143—1150.
Jerger, J., and D. Hayes. 1977. Diagnostic speech audiometry. Arch. Otolaryngol. 103, 216—222.
Jerger, J., and S. Jerger. 1971, Diagnostic significance of PB word functions. Arch. Otolaryngol. 93, 573— 580.
Jerger, J. F., T. W. Tiliman, and J. L. Peterson, 1960. Masking by octave bands of noise in normal and impaired ears. J. Acoust. Soc. Am. 32, 385—390.
Jerger, S.,S. Lewis, J. Hawkins, and J. Jerger. 1980. Pediatric speech intelligibility test. I. Generation of test materials. Int. J. Pediatr. Otorhinolaryngol. 2,217—230.
Jirsa, R. F., W. R. Hodgson, and C. P. Goetzinger. 1975. Unreliability of half-list discrimination tests. J. Am. Aud. Soc. 1, 47—49.
Johnson, C. W., and R. M. Bordenick. 1978. Bone conduction speech reception thresholds with the mentally retarded. J. Aud. Res. 18, 229—235.
Johnson, E. W. 1968. Auditory findings in 200 cases of acoustic neuromas. Arch. Otolaryngol. 88, 598— 603.
Kalikow, D. N., K. N. Stevens, and L. L. Eiiiot. 1977. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J. Acoust. Soc. Am. 61, 1337—1351.
Karlsen, E. A., and C. P. Goetzinger. 1980. An evaluation of speech audiometry by bone conduction in hearing impaired adults. J. Aud. Res. 20, 89—95.
Katz, D. R., and L. L. Elliot. 1978. Development of a new children’s speech discrimination test. Paper presented at American Speech-Language-Hearing Association Convention, Chicago.
Killion. M. C. , Niquette. P. A & Gudmundsen. G. I (2004) Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society or America. 116(4). 2395—2405
Kreul, E. J., J. C. Nixon, K. D. Kryter, D. W. Bell, J.S. Lang, and E. D. Schubert. 1968. A proposed clinical test of speech discrimination. J. Speech Hear. Res. 11,536—553.
Kreul, E. J., D. W. Bell, and J. C. Nixon. 1969. Factors affecting speech discrimination test difficulty. J. Speech Hear. Res. 12, 281—287.
Lehiste, I . and G. E. Peterson. 1959, Linguistic considerations in the study of speech intelligibility. J.Acoust. Soc. Am. 31, 280—286.
Levitt H.; Rabiner L.: 1967.Use of a sequential strategy in speech intelligibility testing. J. Acoust. Soc. Am. 42, 609-612,.
Levitt H.: Adaptive testing in Audiology. Scand. Audiol. Suppl. 6, 241-291, 1978.
Licklider, J. C. R.. and G. A. Miller. 1951. The perception ol speech. in S. S. Stevens, ed. Handbook of Experimental Psychologv John Wiley & Sons, New York.
Linden, A. 1965. Undistorted speech audiometry. in A. Graham, ed. Sensorineural Hearing Processes and Disorders Little, Brown, & Co., Boston.
Loven, F. C . and D. B. Hawkins. 1983. Interlist equivalency of the CID W-22 word lists presented in quiet and in noise. Ear Hear. 4, 91—97.
Lovrinic, J. H., E. J. Burgi, and E. T. Curry. 1968. A comparative evaluation of uve speech discrimination measures. J. Speech Hear. Res. 11, 372—381.
Lynn, G. 1962. Paired PB-50 discrimination test: a preliminary report. J. Aud. Res. 2, 34—36.
Lynn, J. M., and S. R. Brotman. 1981 Perceptual significance of the CID W-22 carrier phrase. Ear Hear. 2, 95—99.
Manning, W. H.. C. K Shaw, J. E. Maki, and D. S Beasley. 1975. Analysis of half-list scores on the PBK-50 as a function of time compression and age.J. Am. Aud. Soc. 3, 109—111.
Marconi L.; Ott M.; Presenti E.; Ratti D.; Tavella M,: 1994.Lessico elementare. Zanichelli, Bologna,.
Margolis, R. 1-1., and J. P Millin. 1971, An item difficulty based speech discrimination test. J Speech Hear. Res. 14, 865—873.
Marshall, L., and S. P. Bacon 1981. Prediction of speech discrimination scores from audiometric data, Ear Rear. 2, 148—155.
Martin, E. S.. and J. M Pickett. 1970. Sensorineural hearing loss and upward spread of masking. J Speech Hear. Res. 13, 426—437.
Martin, F. N, and N. R. Forbis. 1978. The present status of audiometric practice: a follow-up studv Asha 20, 531—541.
Martin, F. N, and C. D. Pennington 1971. Current trends in audiometric practices Asha 13, 671—677.
Martin, F N., R. R Hawkins. and H. A T. Bailey 1962. The nonessentiality of the carrier phrase in phonetically balanced (PB) word testing J. Aud Res. 2, 319—322.
McLennan, R. O , Jr., and A. W. Knox 1975 Patient-controlled deliverv of monosyllabic words in a test of auditory discrimination. J. Speech Hear. Disord.40, 538—543.
McPherson, D. F, and G. K. Pang-Ching. 1979. Development ol a distinctive feature discrimination test J. Aud. Res. 19, 235—246.
Mendel,L., & Danhauer,J. (1997) Audiologic evaluation and management and speech perception assessment San Diego. CA: Singular Publishing Group.
Merrell H. B.. and C. J. Atkinson. 1965. The effect o! selected variables upon discrimination scores. J Aud. Res. 5, 285—292.
Miller, O. A., O. A. Heise, and W. Lichten 1951. The intelligibility of speech as a function of the context of the test materials, J. Exp. Psychol. 41, 329—335.
Nelson, D. A., and J. B. Chaiklin. 1970. Writedown versus talkback scoring and scoring bias in speech discrimination testing J. Speech Hear. Res. 13,645—654.
Nilsson, M.. Soli. S.D., & Gelnett. D. (1996) Development and norming of a hearing in noise test for children House Ear Institute Internal Report. 5.115— 128.
Northern, J. L., and K. W. Hattler. 1974. Evaluation of four speech discrimination test procedures on hearing impaired patients. J. Aud. Res, Suppl. 1, 1— 37,
Olsen, W. 0., and T. W. Tiliman. 1968. Hearing aids and sensorineural hearing loss. Ann. Otol. 77, 717— 727.
Olsen, W.O., Van Tasell. D.J., & Speaks, C. E. (1997) The Carhart Memorial Lecture. American Auditory Society, Salt Lake City. Utah 1996: Phoneme and word recognition for words in isolation and in sentences Ear and Hearing. 18.175—188.
Owens, E. 1961. Intelligibility of words varying in familiarity. J. Speech Hear. Res. 4, 113—129, 1961.
Owens, E., and E. D. Schubert, 1968. The development of consonant items for speech discrimination testing. J. Speech Hear. Res, 11, 656—667.
Owens, F., and E. D. Schubert. 1977. Development of the California Consonant Test. J. Speech Hear. Res. 20, 463—474.
Owens, E., M. Benedict, and E. D. Schubert. 1971. Further investigation of vowel items in multiplechoice speech discrimination testing. J. Speech Hear. Res. 14, 841-847.
Palmer, J. M. 1955. The effect of speaker differences on the intelligibility of phonetically balanced word lists. J, Speech Hear. Disord. 20, 192—195.
Penrod, J P 1978. Discrimination performance on a carrier phrase vs a no carrier phrase speech discrimination task Paper presented at the joint meeting of the Tennessee/Georgia Speech and Hearing Associations. Chattanooga, TN.
Penrod, J P. 1979. Talker effects on word-discrimination scores of adults with sensorineural hearing impairment. J. Speech Hear. Disord. 44, 340—349.
Penrod. J. P. 1980. A comparison of half- vs full-list speech discrimination scores in a hearing impaired geriatric population. J Aud Res. 20, 181-186.
Peterson. G. E.. and I Lehiste. 1962. Revised CNC lists for auditor tests. J. Speech Hear. Disord 27, 62-70.
Pickett, J. M. (1999) The acoustics of speech communication: Fundamentals. speech perception theory. and technology (pp 86—89) Boston:Allyn & Bacon.
Pietrantoni L.; Bocca E.; Agazzi C,: 1956.Diagnosi delle sordità centrali, Relaz. XLIV Congr. Soc. Ital. Laringol. Otol. Rinol.,.
Prinz, I . Nubel, K. & Gross. M. (2002). Digital vs analog hearing aids For children: Is there a method for making an objective comparison possible? HNO. 50(9),844—849.
Prosser S.; Arslan E.; Zecchini B.; Luppi M.P.: 1986.Batteria di prove vocali per la valutazione delle minime capacità uditive, Studio normativo. Acta Otorhinol. Ital. 6, 395-402,.
Resnick. D M 1962. Reliability of the twenty-five word phonetically\ balanced lists. 4 Aud Res. 2, 5-12.
Rimondini P.; Rossi Bartolucci R.: 1982.Approccio alla calibrazione di un reattivo verbale per lo screening in età prescolare. Boll. Ital. Audiol. Foniat. 5, 98-113,.
Roeser,R. (1996) Audiology desk reference New York: Thieme Medical,Publishers .
Ross. M., and D A Huntington. 1962. Concerning the reliability and equivalency of the CID W-22 auditory tests. 4 Aud Res 2, 220—228.
Ross, M , and J. Lerman 1970 A picture identification test for hearing impaired children. .J Speech Hear. Res. 13, 44 53.
Schubert, E D , and F. Owens, 1971 CVC words as test items .J Aud Res. 11, 88—100
Schultz MC.: 1964 Word familiarity infiuences in speech discrimination. journal of Speech and Hearing Research. 7, .395-400,.
Schultz, M C. and E. D Schubert. 1969. A multiple choice discrimination test (MCDT) Laryngoscope 79, .382-399.
Schumaier, D R., and W. I. Rintelmann 1974 Half-list vs full-list discrimination testing in a clinical setting. 4 Aud. Res Suppl. 2, 16-17.
Schwartz, D. M , and R. K. Surr 1979. Three experiments on the California Consonant Test. .J Speech Hear. Disord 44, 61—72.
Schwartz, D. M., F H Bess, and V. D. Larson. 1977 Split-half reliability of two word discrimination tests as a function of primary-to-secondary ratio J. Speech Hear. Disord. 42, 440—445.
Sher, A , and E. Owens 1974 Consonant confusions associated with hearing loss above 2000 Hz. J. Speech Hear. Res 17, 669—681.
Shirinian, M. 4., and D .J Arnst. 1980. PI-PR rollover in a group of aged listeners. Ear Hear. 1, 50—5.3,
Shutts. R E. K 5. Burke, and ‘i E Creston 19(34. Derivation o! twent -five word PB lists 4 Speech Hear Disord 29, 442—447.
Siegenthaler, B. M., and G. Haspiel. 1966. Development of two standardized measures of hearing for speech by children U.S Department of Health, Education and Welfare, Project No 2372, Contract OE-5- 10-003.
Sieganthaler, B. M., and R. Strand. 1964 Audiogram average methods and SRT scores. J. Acoust. Soc. Am. 36, 589—593.
Silverman, S. R., and I. 4. Hirsh. 1955. Problems related to the use of speech in clinical audiometry. Ann. Otol. Rhinol. Laryngol. 64, 1234—1244.
Simone R.: 1988.Fragilità della morfologia e contesti turbati. In GIACALONE RAMAT A. (a cura di): L’italiano tra le altre lingue: strategie di acquisizione. Il Mulino, Bologna,.
Simone R.: 1993.Stabilità e instabilità nei caratteri originali dell’italiano.
In Sobrero A.A. (a cura di): Introduzione all’italiano contemporaneo. Le strutture, Editori Laterza, Bari,.
Solomon, L. N., J. C. Webster, and J. C Curtis. 1960. A factorial study of speech perception. J. Speech Hear. Disord. 3, 101—107.
Speaks, C., and J. Jerger. 1965. Method for measurement of speech identification. 4. Speech Hear. Res.8, 185—194.
Speaks, C., J. Jerger, and S. Jerger. 1966. Performance-intensity characteristics of synthetic sentences. J. Speech Hear. Res. 9, 305—312.
Stach,B.,13(1998) Word-recognition testing: Why not do it well? Hearing Journal. 51. 10—16 .
Thorndike, E. L. 1932. A Teacher’s Word Book of the Twenty Thousand Words Found Most Frequently and Widely in General Reading for Children and Young People Teachers College, Columbia University, New York.
Thorndike, E. L., and I. Lorge 1944. The Teacher’s Word Book of 30,000 Words. Columbia University Press, New York.
Thornton, A. R., and M. J. M. Raffin 1978. Speech discrimination scores modeled as a binomial variable. J Speech Hear. Res. 21, 507—518.
Tillman, T. W., and R. Carhart. 1966. An expanded test far speech discrimination utilizing CNC monosyllabic words: Northwestern University Auditory Test No. 6. Technical report no. SAM-TR-66-55. USAF School of Aerospace Medicine, Brooks Air Force Base, Texas.
Tillman, T. W., and W. 0. Olsen. 1973. Speech audiometry. in J. Jerger, ed. Modern Developments in Audiology, Ed. 2. Academic Press, New York.
Tillman, T. W., R. Carhart, and L. Wilber. 1963. A test far speech discrimination composed of CNC monosyllabic words: Northwestern University Test No. 4. Technical report no. SAM-TDR-62-135 USAF School of Aerospace Medicine, Brooks Air Force Base, Texas.
Tobias, J. V. 1964. On phonemic analysis of speech discrimination tests. 3. Speech Hear. Res. 7, 102— 104.
Townsend, T. H., and D. M. Schwartz. 1981. Error analysis of the California Consonant Test by manner of articulation. Ear Hear. 2, 108-111.
Traul, G N., and J. W. Black. 1965. The effect of content on aural perception of words. J. Speech Hear. Res. 8, 363—369.
Turrini M.; Prosser S.; Fabbri S.: 1988.Impiego di procedure adattive in audiometria vocale, I Care 13, 108-111,.
Valente, M. K., and E. W. Stark. 1977, Bone conducted speech audiometry with normal hearing and hearing-impaired children. J. Aud. Res. 17, 105— 108.
Weber, S., and R. C. Redell. 1976. A sentence test for measuring speech discrimination in children. Audiol Hear. Educ. 2, 25—30, 40.
Veli, 1989.Vocabolario elettronico della lingua italiana. IBM Italia,.
Voghera M.: 1992.Sintassi e intonazione nell’italiano parlato. Il Mulino, Bologna,.
Williams, C., and M. Hecker. 1968. Relation between intelligibility scores for four test methods and three types of speech discrimination. J. Acoust. Soc. Am. 44, 1002-1006.
Wood. S. A,& Lutman. M.E. (2004) Relative benefits of linear analogue and advanced digital hearing aids International Journal of Audiology.43(3). 144—155.
Young, M. A., and E. W. Gibbons. 1962. Speech discrimination scores and threshold measurements in a non-normal hearing population. 3. Aud. Res. 2,21—33.